1.3. Themes and Guiding Principles¶
When describing systems and their behavior, there are three central themes that emerge. The first is that computer systems create a platform for applications, acting as a foundation for advanced work. Using that foundation effectively requires understanding that systems have semiotics, which means that all communication – whether between system components or between the system and the user – exist within a context that influences how messages are interpreted. Lastly, because system designers cannot predict how the system will be used – particularly when the number of users increases – systems entail complexity, leading to unintended properties that may be beneficial or detrimental. The remainder of this book is devoted to addressing these themes, while identifying guiding principles for designing and implementing systems correctly and efficiently.
1.3.1. Systems as Foundations of Computing¶
Computer systems are not built to exist in isolation. Rather, computer systems are platforms intended to create a foundation for advanced applications. As shown in Figure 1.3.1, applications rely on the OS to provide common services, such as access to the file system or network. Some OS components, such as the scheduler, rely solely on the hardware as a platform. Others rely on subsystems within the OS, such as the generic file interface [1]. These subsystems, in turn, rely on the interfaces to hardware components, such as storage devices, memory units, or network cards. In all cases, a higher-level software component is relying on a reactive system that provides service upon request.
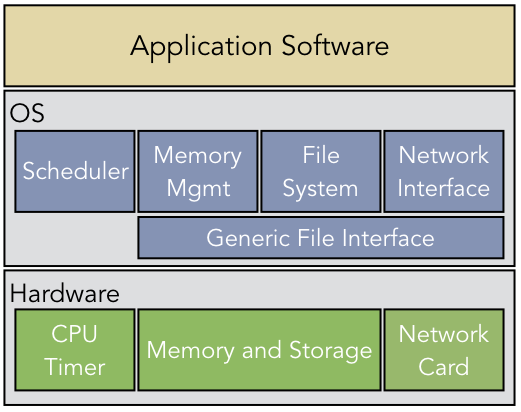
Figure 1.3.1: Applications rely on OS services, built on top of other OS services and hardware
One key factor to consider when designing concurrent systems software is the scarcity of resources. Individual computers have a limited number of CPU cores that can execute software at the same time. Similarly, applications must share access to a finite amount of physical memory resources. Consequently, systems software must explicitly manage and control access to shared resources, so as to prevent applications from interfering with each other or corrupting each other’s work.
In order to manage the scarcity, system designers must address the inherent tradeoffs based on the available resources. There are several common tradeoffs that should be considered. The space/time tradeoff describes the phenomenon that using more resources for a short period of time can lead to faster execution. One example of this is the creation of a buffer for exchanging data. A small buffer would lead to more messages send back and forth, leading to a larger total delay; a large buffer could allow all data to be sent in a single message, but that reduces the memory (space) available for other software running.
A second tradeoff to consider is the interface abstraction. Consider the system design in
Figure 1.3.1, described previously. In this OS design, the network interface,
file system, and memory management all rely on a common interface abstraction that everything is a
file. That is, all of these services should be treated as a sequence of bytes, with an integer file
descriptor used to identify the data stream. This approach allows all of these subsystems to use
common functions read() and write() to interact with the system. However, this generic
interface obscures some key differences between network communications and data stored on a hard
drive. For instance, once a message is retrieved from a network card, the message is removed from
the network card’s internal memory, as if it has been destroyed; that is, an application cannot rely
on the network card to store the message persistently for reference whenever it is needed. On the
other hand, that is exactly the service that files on a hard drive provide. Consequently,
abstracting away these differences provides a common interface, but eliminates the possibility of
optimizing the interface based on the specific hardware component.
Another tradeoff that commonly arises involves security vs. usability. A hard drive can be made perfectly secure by smashing it with a hammer; no malicious adversary would then be able to steal your data, but you would no longer be able to use it either. In a significantly less extreme example, network messages might employ security techniques to ensure all of the data is transferred and only the intended recipient reads it. The downside is that this level of security may be unnecessary and, even worse, the verification procedures involved are too slow for the application to use.
All computer system designs must entail compromises. The scarcity of resources makes it necessary to balance the factors that influence these tradeoffs in order to support higher-level applications effectively. System architects – especially those building systems intended for general-purpose use – must predict what applications will be deployed and how best to balance these factors for the specific context of those applications.
1.3.2. Systems and Complexity¶
Computer systems are complex. This does not simply mean that they are complicated, though that is certainly the case. Taking a system design from specification to implementation requires close attention to details that may not be immediately obvious. Changing the order of two lines of code, using a different compiler option, or inadvertently freeing a pointer at the wrong time can all lead to catastrophic system failures. These are examples of how implementing computer systems is a complicated task that requires special care.
Complexity, on the other hand, means something more than just being complicated. Complexity implies that the system exhibits emergent properties that are not intuitive or obvious from the design. Interactions between entities in a system leads to unintended combinations of behaviors and system configurations. One example of an such unanticipated behavior in an OS is known as Bélády’s anomaly, which describes the unusual scenario where adding more memory resources to a computer actually leads to slower performance. Other emergent properties arise when entities compete for access to shared resources. In deadlock, two or more processes simultaneously block each other’s access in a permanent and unresolvable stalemate; process A has something that process B needs and vice versa, but neither will give up what they possess. In priority inversion, a high-priority task may be prevented from running by a low-priority task.
Networked computers often experience attacks as emergent properties that exploit non-obvious vulnerabilities. One example of such an attack is a syn flood, in which thousands or millions of coordinated nodes send requests for service to the same server. As the server allocates resources to process these requests, it quickly runs out of memory and crashes. Another example is a replay attack on a security protocol. In a replay attack, a malicious adversary snoops on network traffic and observes that a user was successfully logged in after sending a particular message; the adversary does not actually know what the message says, but they send it anyway and are also granted access.
In all of these cases, complexity is the result of unanticipated sequences of actions that lead to new and unusual configurations. As a result, computer system designers must accept that reliability is elusive. When a system is designed and implemented, the developers routinely perform a number of tests to convince themselves that the system behavior is correct. However, these testing procedures are inherently limited and cannot provide strong assurances. Given this challenge, many systems are designed to use redundancy to overcome probabilistic errors.

Example 1.3.1
To illustrate how redundancy provides reliability, consider a system component that has a 1% probability (p = 0.01) of failing within a particular time frame. Adding a second copy as a back-up, decreases the probability of that component failing to 0.01% (p = 0.01 * 0.01 = 0.0001), as an overall failure requires both copies to fail at the same time. Adding a third copy as backup decreases the probability to 0.0001% (p = 0.01 * 0.01 * 0.01).
Example 1.3.2
As another example of reliability through redundancy, consider the TCP network protocol. In TCP, a device sends a segment of information to another device, waiting for a response. If the response does not arrive within a pre-designated time frame, TCP resends the message but increases the waiting time limit. Note that increasing the wait time has the effect of reducing the probability of failing to get the response back in time. For instance, maybe the first time limit was 10 ms, but the response actually took 12 ms. For the second message, the time limit was increased to 15 ms, so the 12 ms response time is acceptable. Sending redundant messages, especially when the time limit for receiving a response is increased, improves the overall reliability of the protocol.
Computer systems designers and developers must also accept that system complexity breeds misunderstanding. In many cases, the root causes of an error or failure are hidden by the complexity. Since errors and other emergent properties arise from unanticipated sequences of actions, anyone trying to debug the system afterward might not have enough information to determine what went wrong; the system simply may not have been logging the most relevant information to reconstruct the cause. As an example, consider the following line of C code:
printf ("hello, %s", user);
Assume that the system has crashed, and the developer is using this line as a hint for debugging.
After examining the output, the developer observes no mention of this line of code and concludes
that the error occurred before this point. Further investigation reveals that the user pointer
was initialized correctly, so this line of code did not cause the segmentation
fault.
Without closer investigation, it is possible that any of those claims were wrong. The user
variable may have been initialized correctly, but another part of the code may have corrupted the
pointer, making it null. Alternatively, the null-byte at the end of the string may have been
modified, converting the user string “Alice” to turn into “Alice&76as87d92f00d9f8…” If that
new string is long enough (before encountering another null-byte, the parameter would overflow the
stack in an internal library function.
Even worse for debugging, this line may have been executed successfully without error. Observe
that the printed string does not end with a '\n'. When this happens, printf() does not
necessarily cause the message to be printed immediately. Rather, the message gets placed into a
buffer for printing when the buffer gets flushed. If the program crashes before the buffer is
flushed, the message is simply lost. Consequently, when debugging complex systems, it is critically
important to use the correct tools; relying on print statements is no longer sufficient, as they may
cause you to look in the wrong place.
1.3.3. The Semiotics of Computer Systems¶
The term semiotics [2] describes the use and interpretation of symbols and signs. That is, semiotics focuses on how communication should be interpreted based on the language used and the context of the messages. Understanding the semiotics of a message involves considering the relevant syntax, semantics, and pragmatics. The syntax defines to the rules that control how symbols can be combined to create a message. The semantics define the meaning of the individual symbols. The pragmatics characterize the relationship between the message and the entity making sense of the message. The semiotics of computer systems can be explored along three dimensions: machine-to-machine, machine-to-human, and machine-to-world.
The first dimension – and the most well understood – focuses on the communication between two computer systems. That is, when two systems need to exchange information, what data structures, communication protocols, and applications will be involved? In Computer Systems: A Programmer’s Perspective [Bryant2015], Bryant and O’Hallaron capture this idea with the statement that information = bits + context. That is, computers store data in binary form (bits) that conveys no meaning without applying the relevant context. The semiotics view of systems expands Bryant and O’Hallaron’s statement by distinguishing the semantics (what the symbols mean) from the pragmatics (what the computer does in response).
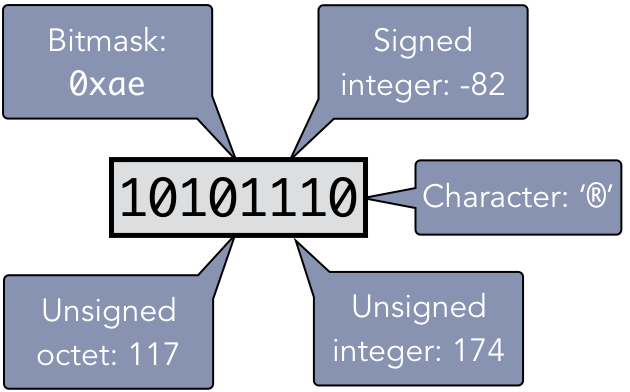
Figure 1.3.4: The same sequence of 8 bits can have several possible semantics
The syntax dimension of semiotics imposes a structure on the bits; a simple example of this structure is the fact that binary data is typically read as bytes – groups of eight bits. Consider the bits shown in Figure 1.3.4. The semantics of byte indicate that the least-significant bit is placed on the right, yielding the unsigned integer value 174 or the signed integer -82. Applying the semantics of characters would yield the value ‘®’. An octet is another numeric semantic interpretation group of eight bits, but with the least-significant bit on the left; this octet has the decimal value 117. The pragmatics of the context implies whether or not the program in question can read that kind of file.
Example 1.3.3
To make these terms more concrete within the context of computing, consider the outputs of calling
the hexdump command-line utility on two files (for the latter, only selected lines are shown):
$ hexdump -C data.xml
00000000 3c 6d 65 6e 75 3e 3c 6f 70 74 69 6f 6e 3e 4f 70 |<menu><option>Op|
00000010 65 6e 20 46 69 6c 65 3c 2f 6f 70 74 69 6f 6e 3e |en File</option>|
00000020 3c 2f 6d 65 6e 75 3e 0a |</menu>.|
00000028
$ hexdump -C data.mp3 | head -n 150 | tail -n 3
000024d0 03 11 00 3f 00 fe 9d 6f f4 d3 3e 8b a8 4c 23 8a |...?...o..>..L#.|
000024e0 e6 2b d9 8c 37 70 18 8a 23 45 6a 03 a2 bc 6e 11 |.+..7p..#Ej...n.|
000024f0 dd 60 31 99 50 4c 1e de 44 93 7b 38 b7 12 35 77 |.`1.PL..D.{8..5w|
Different programs will read and interpret these files in distinct ways, starting with the syntax. The syntax declares how the file contents must be structured. If the program is expecting XML, it would expect the human-readable text structure as shown in the first file. A program expecting XML would not be able to interpret the latter file successfully. A media player program, on the other hand, would know how to interpet the binary data structures of the second file.
The semantics of the system then define what the file contents mean. For instance, the XML data is
intended to indicate that a user should be shown a menu that allows a user to open a file; it is
unlikely that the creator of the file intended this XML code to express how much they liked a movie
they saw. The semantics of the symbol "<menu>" has an intended meaning that the message is
conveying. As for the pragmatics, consider what would happen if you opened the MP3 file in an audio
player as compared to a text editor. There is a relationship between the MP3 file (the message) and
the audio player (the entity interpreting the message) that does not exist between the MP3 file and
the text editor.
The second way to consider the semiotics of computer systems is to examine how computer systems and humans interact. In applications programming, this dimension includes usability concerns. In the systems realm, understanding the syntax and the semantics entails learning a variety of functions that define the API for interacting with the OS and the hardware. Computer systems provide many services that can be used to exchange information between applications and coordinate the intended work. Much of this book is devoted to explaining and documenting these APIs and how to use them.
At the same time, it is vital to address the pragmatics of computer systems-to-human interactions, as human cognition and automated computation differ. Some concepts, such as multitasking (“doing multiple things at the same time”), mean different things to humans and to computer systems. To illustrate this concept, consider the following two lines of C code:
x = x + 1; x = x - 1;
Assuming the variable x had an initial value of 5, what would be the result of executing these two lines of code “at the same time”? Our intuition is that these lines of code are not literally executed at the same physical moment, as they contradict one another. Instead, “at the same time” to us means “at approximately the same moment” rather than the literal interpretation. The next question we could ask, then, would be what final value of x should be expected. It may come as a surprise that, after executing both of these statements “at approximately the same moment”, x could end up with three possible final values: 4, 5, or 6. Understanding and addressing the differences between human cognition and computing requires acknowledging the pragmatics of machine-to-human interactions.
The third dimension, which is of particular interest (but not limited) to those who design and build embedded systems, is the relationship between the computer and the physical world. An embedded system is one in which computing is integrated into a larger system that is not obviously devoted to computation; examples of embedded systems include robotics, non-autonomous (i.e., not self-driving) automobiles, or entertainment systems. The key insight to this dimension of semiotics is that the computer itself is a model. That is, anything that can be achieved with the computer can only ever be a simplified approximation of the world.
Another way to describe this issue is to note that computing is built on a digital (or discrete) simulation of a world that is inherently analog (or continuous) in nature. One simple illustration of this fact is to consider floating-point representations of real numbers. There are more real numbers between 0 and 1 than we can store by combining all of the computing resources in the entire world. That is often not a problem, as 0.1999999999999999 is a close enough approximation of 0.2 for practical uses. [3]
This digital approximate of analog phenomena can be found in other aspects of computing. For instance, the very notion of a bit 0 or 1 is created by denoting whether or not an electrical device measures a voltage above or below a given threshold. Devices can also be placed into a high impedance state, in which the value of a bit is neither 0 nor 1. Similarly, time is a continuous physical phenomenon that is not measured identically. Many computers create a discrete approximation of time by measuring the vibrations produced by a crystal subjected to an electric charge. If we were to zoom in on the measurements, there would be slight variations that can neither be predicted nor controlled.
This last factor – time – is the most relevant to the discussion in this book. Concurrent computer systems are, by definition, focused on coordinating the execution of software that is intended to perform multiple tasks at more or less the same time. To accomplish this goal, the system designer must take steps to inject timing controls – synchronization – into the implementation. At the same time, the designer must learn to recognize that there are limits to what can be accomplished regarding time. As this book progresses, time will become a central theme, leading to some well-established but counterintuitive results that the challenge of time makes certain goals – such as getting concurrent systems to agree on what time it is – are impossible.
| [1] | Our perspective of the OS structure derives from the UNIX and Linux design, in which all devices are files. |
| [2] | Semiotics are commonly studied in human-centered fields of study, such as sociology or anthropology. However, approaching the study of computer systems from this perspective allows one to examine nuanced features of this field that lead to mistakes and failures. |
| [3] | The choice of 0.2 was intentional here. The standard floating-point representation, IEEE 754 format, cannot represent the exact value 0.2, as it cannot be written as a finite summation of powers of two. |