4.5. TCP Socket Programming: HTTP¶
Processes running at the application layer of the protocol stack are not fundamentally different
from non-networked concurrent applications. The process has a virtual memory space, can exchange
data through IPC channels, may interact with users through STDIN and STDOUT, and so on. The
primary differences between such distributed application processes and non-networked processes are
that the data is exchanged via an IPC channel based on a predefined communication protocol,
and that channel has a significantly higher likelihood of intermittent communication failures. The
peer process on the other host may be built by the same development team, it may be a customized
open-source server, or it may be a proprietary network service. So long as both processes agree to
abide by the protocol specification, writing distributed applications is not drastically different
from other concurrent applications with IPC. In this section, we will demonstrate how to use TCP
sockets to implement the basic functionality of HTTP, the protocol that underlies web-based
technologies.
4.5.1. Hypertext Transfer Protocol (HTTP)¶
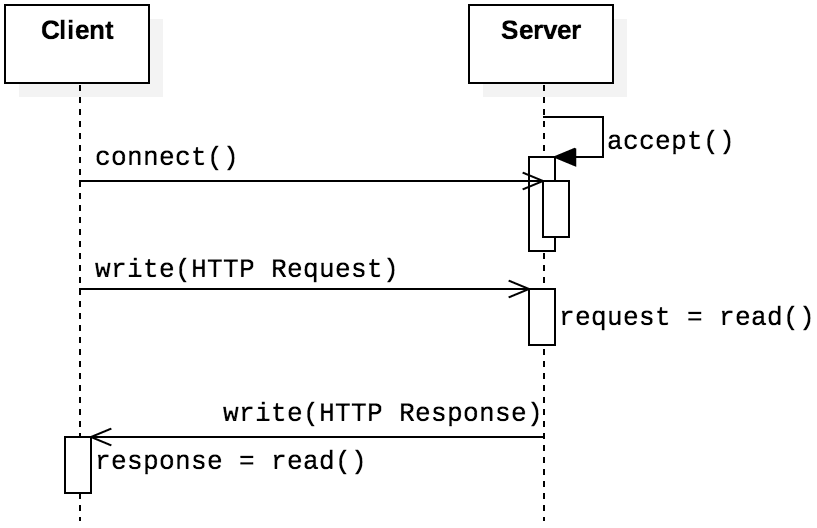
Figure 4.5.1: Basic request-response structure of HTTP running on top of TCP
HTTP is the protocol that defines communication for web browsers and servers. Readers who have built personal or professional web pages have relied on this protocol, even if they were unaware of the details of its operation. HTTP is a simple request-response protocol, defined in RFC 2616. To be precise, HTTP is a stateless protocol, in the sense that neither the client nor the server preserves any state information between requests; the server processes each request independently from those that arrived previously. HTTP applications use TCP connections for their transport layer, and Figure 4.5.1 shows the basic structure of HTTP in relation to the functions that establish the socket connection. The client—a web browser—sends an HTTP request to the server and receives a response.

Example 4.5.1
Both HTTP requests and responses begin with a sequence of header lines, each ending in a
two-character sequence denoted as CRLF (carriage return-line feed, or "\r\n" in C strings).
The first line of requests must be a designated Request or Response line, which must adhere
to a given structure. After the first line, all other headers are optional, but they provide the
client and server with additional useful information. At the end of the header lines, there is a
single blank line (consisting of only CRLF). The figure below shows a sample HTTP
header for a GET request, which is the type of request that indicates the client is asking for a
copy of a file; in contrast a POST request occurs when the client is writing data back to the
server. In the figure below, the client is requesting
http://example.com/index.html, based on a link from https://link.from.com.

Figure 4.5.3: Sample HTTP headers for a GET request
The netcat tool is a useful way to explore the details of HTTP without a web browser. [1]
Using netcat, you can interact directly with a remote HTTP server, typing the lines of the
protocol itself. This tool is useful for text-based protocols like HTTP but cannot easily be used
for protocols that use binary-formatted data. Consider the following example of a command-line
session with netcat:
$ netcat -v example.com 80
Warning: Inverse name lookup failed for `93.184.216.34'
example.com [93.184.216.34] 80 (http) open
GET / HTTP/1.1
Host: example.com
Connection: close
HTTP/1.1 200 OK
[...more lines here, omitted for brevity...]
To use netcat, you specify the hostname (example.com) and the port number (80) to access.
After the command prompt, the first two lines are printed by netcat (in verbose mode with the
-v flag) to indicate that it has connected to the server. The next four lines (the GET,
Host, Connection, and blank lines) were typed manually by the user to request the contents
of http://example.com/. The Host is required for HTTP/1.1, as many web servers are operated
by third-party providers. In the case of example.com, the web server is operated by a cloud
service provider, fastly.net. That is, the server at 93.184.216.34 is not serving content
exclusively for example.com; there are several other domains that can be accessed from the same
IP address. The Host header, then, tells fastly.net which specific domain name you are
trying to reach. The lines beginning with HTTP/1.1 200 OK are the response from the server. The
structure of an HTTP response is explained below. We omit the full response here, as it consists of
several lines of HTTP headers and HTML code that are not critical to the current discussion.
Writing the messages for an HTTP header is straightforward, as the headers are just concatenated
text output. Code Listing 4.11 illustrates the general structure of this task. The client creates a
buffer and copies the required Request line into the beginning. The string concatenation
function, strncat(), appends the other lines to the buffer, and the buffer is written to the
socket. Note that the length variable is used to keep track of how much available space is
remaining in the buffer, which is always the capacity (500) minus the length of the existing string
in the buffer.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | /* Code Listing 4.11:
Constructing and sending an HTTP GET request
*/
size_t length = 500;
char buffer[length + 1];
memset (buffer, 0, sizeof (buffer));
/* Copy first line in and shrink the remaining length available */
strncpy (buffer, "GET /web/index.html HTTP/1.0\r\n", length);
length = 500 - strlen (buffer);
/* Concatenate each additional header line */
strncat (buffer, "Accept: text/html\r\n", length);
length = 500 - strlen (buffer);
/* Other lines are similar and omitted... */
write (socketfd, buffer, strlen (buffer));
|

Bug Warning
C’s string functions are notorious sources of buffer overflow vulnerabilities. One common way these vulnerabilities arise is with repeated calls to strncat(), such as the omitted lines in Code Listing 4.11. The problem is that each call reduces the amount of space left in the buffer. As this happens, the length parameter passed to strncat() each time must shrink to match only the remaining size of the buffer, not the original size. Using the original size each time would create the possibility that strings would be concatenated beyond the end of the buffer.
Example 4.5.2
The figure below shows a sample response from a web server for the request in
Example 4.5.1. The response begins with a required Response line that lets the
client know the request was successful. The optional headers indicate that the body of the message
(after the blank line) consists of 37 bytes of HTML text. (Note that the body of the message in
Example 4.5.1 was empty, which is typical for GET requests.) The body of the
response is the contents of the file index.html stored in the web server’s designated root
directory. The newline character at the end of the HTML code is not required by the HTTP protocol;
rather, it is simply a character stored in the file, as most text editors place a newline at the
end of the file. From the perspective of HTTP, the body of the message is a meaningless stream of
bytes; the content type only matters to the client (the web browser) so that the client knows how
to handle the data. Specifically, the second line of the message body is an HTML header, demarcated
with the <head>...</head> tag structure. This header has no meaning to HTTP itself.

Figure 4.5.6: Sample HTTP response to the request from Example 4.5.1
4.5.2. BNF Protocol Specification¶
The key features of the HTTP specification in RFC 2616 are structured as BNF declarations. To
understand how these declarations structure the protocol, consider the required request and response
lines. Every HTTP request must begin with a Request-Line and every response must begin with a Status-Line:
Request-Line = Method SP Request-URI SP HTTP-Version CRLF
Status-Line = HTTP-Version SP Status-Code SP Reason-Phrase CRLF
The SP designates a space while CRLF designates the carriage return-line feed. Although
whitespace is typically insignificant in HTML, it is significant when processing HTTP headers;
spaces and CRLF characters are required in particular places to facilitate correct
interpretations. For requests, there are several valid Methods that can be used, with GET
and POST being the two most common. A GET request corresponds to reading a file to display
in the web browser; the body of the request would be empty in that case. A POST request, on the
other hand, occurs when the web browser is sending data back to the server, such as when a user
enters data in a form and submits it; the message body after the blank line contain the data to
send, which would contain the form contents.
Readers with experience writing HTML code may be familiar with query strings
and cookies. As described previously, a query is part of the standard URI structure
that begins with a '?' and can provide information to the server about how to process the
request. For instance, the URL http://example.com/help.html?topic=login indicates that the user
is looking for help logging in. The Request-URI in this case is /help.html?topic=login,
containing the query string. [2] Cookies, on the other hand, are another technology used to
provide data to the server; for instance, a cookie may contain an authentication token or a username
to keep track of the user from one request to the next. Cookies are stored in their own HTTP header,
but they are not described in RFC 2616. Instead, there is a separate RFC 6265 that defines the
structure of cookies and how to use them. Ultimately, though, from the perspective of HTTP describe
above, cookies are simply small pieces of data stored in another optional header field.
4.5.3. HTTP/1.1 Persistent Connections¶
The last part of an HTTP Request-Line is the version, which corresponds to the first field of
the Status-Line that begins the response. The examples in Example 4.5.1 and
Example GetResponseEx used the version HTTP/1.0, which is the basic request-response
protocol we have discussed so far. HTTP/1.1 introduces persistent connections, which are commonly used in modern web applications. With a standard HTTP/1.0 request,
the TCP socket connection is closed when the server sends the response. As such, if a client needs
to request more data, the client must establish a new connection and start over. With an HTTP/1.1
persistent connection, the TCP connection is only closed after the client sends a request that
explicitly asks to close the connection.
1 2 3 4 5 6 7 8 9 10 | <!-- Code Listing 4.12:
HTML code that causes the sequence in Figure 4.6 -->
<html>
<head>
<script src="http://zoo.com/library.js" />
<script src="script.js" />
</head>
<body><img src="logo.png" /></body>
</html>
|
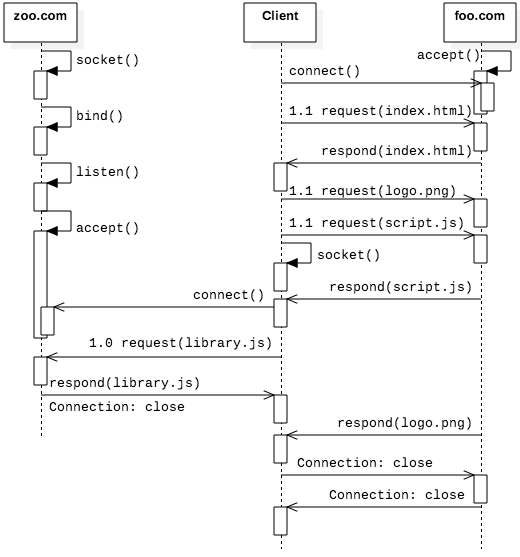
Figure 4.5.7: Requesting four objects with HTTP/1.1 and a fourth object with HTTP/1.0 from a second server
Figure 4.5.7 illustrates a sample scenario that benefits from HTTP/1.1. The client
connects to foo.com and requests the file index.html, which is shown in Code Listing 4.12. This file references two more files, script.js and logo.png, that are both
stored on foo.com. These additional files are retrieved with separate HTTP requests. These
requests are asynchronous, so the client can do other work while waiting for them. While
waiting, the client connects to zoo.com with a request for library.js. Since this is the
only file needed from that server, the client uses HTTP/1.0, which closes the socket immediately.
Since the requests to foo.com used HTTP/1.1, the client must explicitly send a separate request to
close the connection once all files have been received.
The asynchronous requests shown in Figure 4.5.7 are common in modern web designs. These applications frequently augment HTML with JavaScript to create a dynamic and interactive web page; for instance, clicking on a button may produce a drop-down box of menu options to appear. In some cases, the JavaScript code may issue asynchronous HTTP requests. In truth, the web browser issues the request, as all client-side software (including JavaScript) runs as part of the browser process. These requests are standard HTTP requests as we have observed, with the exception that the browser uses multiple threads of execution to issue that request and wait for the response while doing other work. When the browser receives the HTTP response, it will invoke a JavaScript callback routine that the script declared ahead of time to be responsible for handling the data. The web page’s URL does not appear to change, but it is possible to observe these requests as they happen. Most popular web browsers include a menu option, typically called something like “Developer Tools,” that can monitor and even modify these requests.
To be clear, the use of persistent TCP connections does not change the nature of HTTP as a stateless protocol. Although the TCP connection will remain open from one request to the next, the server does not maintain any local information about the specifics of the previous HTTP request or how it responded. The persistent connection is simply a performance improvement, and each request-response is considered a distinct, unrelated exchange.
4.5.4. Processing HTTP Headers¶
After the HTTP-Version, the remainder of the HTTP response Status-Line provides information
to the client about whether or not the request was successful. The status is reported both as a
number (Status-Code) and a text description (Reason-Phrase). Table 4.5
describes several of the most common statuses. The Reason-Phrases shown here are used by
convention and they have no specific effect on processing the response; a web server could choose to
break this convention with arbitrary Reason-Phrases and the response would still be processed
identically.
| Status | Reason-Phrase | Purpose |
|---|---|---|
| 200 | OK | Request was successful |
| 301 | Moved Permanently | File has been moved to a new location |
| 400 | Bad Request | The HTTP request had incorrect syntax |
| 401 | Unauthorized | The request requires user authentication |
| 403 | Forbidden | Access to the resource is not allowed |
| 404 | Not Found | No file was found based on Request-URI |
| 500 | Internal Server Error | The server had an unexpected error or fault |
| 503 | Service Unavailable | The server is unavailable or not accepting new requests |
Table 4.5: Common HTTP response status messages and their meanings
Some status codes are unrecoverable error messages. For instance, if a client receives 404 or 503
message, either the requested file does not exist or the server is down. There is nothing that the
web browser can do to correct those situations, and the browser simply displays an error message.
Other codes do allow the browser to respond automatically. If the server responds with a 301 status,
the HTTP response should include a Location header that designates the new location; this may be a
different URI on the same server, or it might be a full URL because the domain name is different.
Web browsers can read this header and re-issue a new HTTP request based on this new location. As
another example, if the server responds with a 401 status, the response must include a
WWW-Authenticate header with a challenge. The browser may re-issue the request with an added
Authorization header field that stores credentials to respond to the challenge.
Although writing HTTP headers—as shown in Code Listing 4.11—is straightforward,
reading them at the other end can be a challenge if not handled properly. The difficulty arises from
the fact that header sizes vary, so the receiver does not know how many bytes to request from the
socket at a time. To address this challenge, both clients and servers typically impose a maximum
header size of 8 KB by convention. The initial read from the socket requests this much data. If a
complete header is not found in this space, then the connection is terminated as invalid by clients;
servers that receive such invalid headers return Status 413 to indicate Entity Too Large. A
complete header must end with a blank line, creating the four-byte sequence "\r\n\r\n". Code
Listing 4.13 demonstrates how to perform this check by looking for this string. If it is
found, the second '\r' is replaced with the null-byte '\0' to convert buffer to a
complete string of the header, with each header line ending in CRLF.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | /* Code Listing 4.13:
Checking for a complete HTTP response header
*/
#define HEADER_MAX 8192
/* Allocate a buffer to handle initial responses up to 8 KB */
char *buffer = calloc (HEADER_MAX + 1, sizeof (char));
ssize_t bytes = read (socketfd, buffer, HEADER_MAX);
assert (bytes > 0);
/* Look for the end-of-header (eoh) CRLF CRLF substring; if
not found, then the header size is too large */
char *eoh = strnstr (buffer, "\r\n\r\n", HEADER_MAX);
if (eoh == NULL)
{
fprintf (stderr, "Header exceeds 8 KB maximum\n");
close (socketfd);
return EXIT_FAILURE;
}
/* Replace the blank line of CRLF CRLF with \0 to split the
header and body */
eoh[2] = '\0';
|
Once the header and body have been split, processing the header involves repeatedly breaking it at
the CRLF locations. Code Listing 4.14 extends Code Listing 4.13 to
demonstrate this processing, printing all header lines but looking specifically for the
Content-Length header. Since Code Listing 4.13 ended by replacing the blank line of
CRLF CRLF with the null byte, line 25 will set eol to NULL after the last header line is
processed.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | /* Code Listing 4.14:
Extending Code Listing 4.13 to read a header line at a time
*/
/* Print each header line, with eol indicating the location
of CRLF at the end-of-line */
char *line = buffer;
char *eol = strstr (line, "\r\n");
size_t body_length = 0;
while (eol != NULL)
{
/* Null-terminate the line by replacing CRLF with \0 */
*eol = '\0';
printf ("HEADER LINE: %s\n", line);
/* Get the intended body length (in bytes) */
if (! strncmp (line, "Content-Length: ", 16))
{
char *len = strchr (line, ' ') + 1;
body_length = strtol (len, NULL, 10);
}
/* Move the line pointer to the next line */
line = eol + 2;
eol = strstr (line, "\r\n");
}
|
After Code Listing 4.14 establishes the Content-Length of the message (either request
or response), this length can be compared with the length of the body that was already read. That
is, the initial read from the socket received no more than 8 KB of data, which was the maximum size
of the header. However, the body contents (particular for HTML data, images, and other objects
returned as a response) are likely to exceed this 8 KB size limit. Consequently, an additional
read() may be required to retrieve the rest of the body contents. Code Listing 4.15
completes the response processing by duplicating the body contents received so far and resizing it
to read in the additional data. Note that line 12 will read from the socket into the space just after
the existing body contents.
1 2 3 4 5 6 7 8 9 10 11 12 13 | /* Code Listing 4.15:
Extending Code Listing 4.13 to read a header line at a time
*/
char *body = strdup (eoh + 4);
if (body_length > strlen (body)) // if false, all data received
{
/* Increase the body size and read additional data from the
socket; the number of bytes to request is the Content-Length
field minus the number of bytes already received */
body = realloc (body, body_length);
bytes = read (socketfd, body + strlen (body), body_length - strlen (body));
}
|
In Code Listings 4.13, 4.14, and 4.15, we have been
implicitly assuming the data was HTML for simplicity. The response header would declare this with
the Content-Type header. However, the same principle ideas would apply regardless of the type of
data requested. For instance, if the client issues a GET request for /logo.png, the response
would start with the same headers we have used, but the Content-Type would inform the client
that the body contains image/png instead of text/html. Given that images can contain the
null-byte, Code Listing 4.13 and Code Listing 4.15 would need to be
modified to avoid the use of strlen(). However, the code shown here could be adapted to support
binary data objects, such as images.
4.5.5. Persistent State with Cookies¶
Designing HTTP to be stateless worked well for its original purpose of sending and receiving documents. As the uses of web pages and the Internet have evolved, however, the lack of state information became a hindrance. Developers began to use HTTP as the foundation for web-based applications that required state persistence. As an example, consider a web-based email serice. The first request might allow a user to log into the system, then a second request would retrieve the messages in the user’s inbox. Additional requests would retrieve pages for composing new messages and sending them. Clearly, such an application design would benefit from storing persistent information on the server about the user.
In modern web development, there are multiple options for data persistence. HTTP cookies are one of the oldest and most pervasive tools to accomplish this. A cookie is a short,
text-based key-value pair that gets sent as an HTTP header field (similar to the Content-Length
or Connection headers previously discussed). Code Listing 4.16 demonstrates one way
to create a cookie in Javascript.
1 2 3 4 5 6 7 8 9 | /* Code Listing 4.16:
Creating a new cookie in Javascript that expires in 15 minutes
*/
var date = new Date();
date.setTime(date.getTime() + 15 * 60 * 1000); // add 15 minutes
var newCookie = "username=julian;expires=" + date.toUTCString() +
";path=/;samesite=strict;secure";
document.cookie = newCookie;
|
The Javascript code in Code Listing 4.16 would run on the client side, causing the web browser to
create a new cookie as the key-value pair username=julian. The rest of lines 7 and 8 control how
the browser will use the cookie. The expires field indicates that the cookie is only valid for
the next 15 minutes; it will be deleted after that time has passed. The path=/ indicates that
this cookie will be sent along with any requests for the current domain name, regardless of the web
site’s directory structure. The samesite=strict prevents the cookie from being sent to
third-party web sites; that is, the cookie will not be sent to other domains, such as advertising
networks. Lastly, the secure restricts the cookie to transfer over HTTPS and will prevent its
transfer over standard HTTP. Line 9 adds the new cookie to the browser’s document.cookie value,
which is the concatenated list of all cookies. (This line is unintuitive, as Javascript uses the
assignment operator for this purpose, but the line is actually appending the value to an existing
string.)
Once the browser executes the code in Code Listing 4.16, future HTTPS requests that
occur in the next 15 minutes will contain the HTTP header line Cookie: username=julian\r\n. Note
that the header line does not contain information about the expiration date or the other fields, as
these are only relevant to the browser. As an alternative, the server could also generate the
cookie. The primary differences are that the HTTP header line would include all of the fields:
Set-Cookie: username=julian;expires=Sat, 15 May 2021 16:00:00 GMT;
path=/;samesite=strict;secure
To add persistent state to the HTTP exchange, the server would use a database that mapped the cookie
username=julian to information about the user. As such, the server-side code would be able to
connect a new request to previous requests, creating the history needed for the application. One
common technique, even without a specific user login mechanism, is to use a session cookie,
such as session=182735927341. Session cookies persist until the web browser is closed, allowing
servers an easy way to link requests from the same web browser as likely to be related.
| [1] | While netcat is useful for exploring protocols, it sends all data in unencrypted form
and cannot be used for any form of secure communication. |
| [2] | Using query strings with standard HTML files is pointless, as HTML is a static formatting language and cannot respond to input. Other server-side technologies, such as Java servlets, PHP, or Apache Server-Side Includes (SSI) are required to handle the query dynamically. |