10.4. Arrays, Structs, Enums, and Type Definitions¶
As with other common typed languages (such as Java), C supports arrays of other types. When
declaring an array, the compiler must be able to determine the exact length. One way to do this is
to specify the length inside the brackets of the declaration (such as int array[10];). Another
way is to provide an explicit initialization array. Code Listing A.11 demonstrates this
second technique, omitting the length from inside the brackets on line 6 (although it could be
included here).
1 2 3 4 5 6 7 8 9 | /* Code Listing A.11:
C array names are implicitly pointers to their first entry
*/
/* Instantiate an array and print its starting address */
uint32_t data[] = { 1, 2, 3, 4, 5 };
printf ("data = %p\n", data);
printf ("&data = %p\n", &data);
printf ("&data[0] = %p\n\n", &data[0]);
|
Code Listing A.11 illustrates a key aspect of the relationship between arrays and
pointers: Array names are implicitly pointers to their first element. To see this, consider
lines 7 – 9; line 7 prints the value of data, line 8 prints the address of data, and line 9
prints the address of data[0]. When this program is run, these three lines produce the same
value as the output. The convention in C is that any array variable is an alias for the starting
address. All three of these notations can be used (and frequently are) depending on the context and
style preferences of the programmer.
Code Listing A.12 extends the previous example to explore the relationship between
arrays and pointers further. Line 7 starts by declaring a pointer and initializing it to point to
the array. On this line, we could also initialize u32ptr = &data[0], but (due to convoluted type
checking rules) it is a compiler warning to initialize u32ptr = &data (despite the fact that
data and &data are the same). Line 8 sets the walker pointer in the same way.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | /* Code Listing A.12:
C arrays and pointer arithmetic work identically
*/
/* Make two pointers to data, which also means they point to
the first element in the array */
uint32_t *u32ptr = data; // &data[0] is also ok, &data is not
uint32_t *walker = data; // a second pointer to data
/* Loop through the elements, observing that array bracket
notation and pointer arithmetic behave identically; after
each time through the loop, advance the walker pointer */
for (size_t i = 0; i < 5; i++, walker++)
{
printf ("data[%zd] address %p and value %08" PRIx32 "\n",
i, &data[i], data[i]);
printf ("u32ptr[%zd] address %p and value %08" PRIx32 "\n",
i, &u32ptr[i], u32ptr[i]);
printf ("u32ptr+%zd address %p and value %08" PRIx32 "\n\n",
i, u32ptr + i, *(u32ptr + i));
printf ("walker address %p and value %08" PRIx32 "\n\n",
walker, *walker);
}
|
Lines 13 – 23 in Code Listing A.12 demonstrate the equivalency between array
dereferencing and pointer arithmetic. That is, when C performs an operation like u32ptr +
5, it is not simply the value of u32ptr plus the number 5 in standard arithmetic; instead,
u32ptr + 5 requires taking the value of u32ptr (which is an address) and adding 5 times the
size of what u32ptr points to. In this case, if u32ptr stores the address 0x7ffee0000720,
u32ptr + 5 would add 20 to this value (since u32ptr is a pointer to 4-byte uint32_t
values), yielding 0x7ffee0000734. In general terms, for an arbitrary pointer ptr,
&ptr[n] and ptr+n are identical for any integer n; ptr[n] and *(ptr+n) also
yield the same value. (As the bracket notation tends to be more familiar, many C programmers use it
whenever pointer arithmetic is needed.)
Lines 21 and 22 do not require adding any value to the walker pointer so that it accesses the
correct location. Instead, walker is set up to walk through the array, accessing one element at a
time. Specifically, line 8 initializes walker to point to the first element, and the increment
field of the for-loop causes walker to advance after each iteration (line 13). (Observe that it is
possible to specify multiple increments in a for-loop, separated by a comma as shown with i++,
walker++.) A subtle aspect of this increment is that it does not simply add 1 to the address
walker is pointing to; rather, just like the additions on lines 18 and 20, walker++ will
increment the address by the size of a uint32_t. Consequently, this incrementing style is a
common technique to use a pointer to traverse through the elements of an array.
Although pointer variables can be treated as arrays, the reverse is not true. That is, even though
an array name is implicitly a pointer to the first element of the array, we cannot use pointer
notation for a variable declared as an array. In Code Listing A.11 and A.12, trying to access *data or *(data+i) would produce a compiler error.
Code Listing A.13 illustrates a slight variation on Code Listing A.12. In
this scenario, data is declared as an array of 32-bit values. Since the array consists of two of
these values, the array occupies eight consecutive bytes of memory. Line 12 declares a pointer like
before, but the pointer is a uint8_t*, so it points to 8-bit values. Lines 13 – 19 will traverse
through all of the bytes of the data array, but accessing it a byte at a time instead of just
examining the two 32-bit entries. One advantage of this approach is that using a uint8_t*
pointer provides a mechanism to explore the endianness of multi-byte integers. In this example,
data[0] stores the 32-bit value 0x01020304, spread across four memory locations. Assuming
this runs on a little-endian architecture (such as x86), 0x04 is stored at the first of these four
byte locations; consequently, u8ptr[0] accesses 0x04, u8ptr[1] access 0x03, and so
on. Once the loop would get to u8ptr[4], the result would be 0x08, which is the first byte
stored for data[1].
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | /* Code Listing A.13:
Using a pointer to traverse an array of a different size
*/
/* Instantiate an array of two 32-bit integers */
uint32_t data[] = { 0x01020304, 0x05060708 };
printf ("data starts at %p\n", data);
printf ("data[0] address %p and value %08" PRIx32 "\n", &data[0], data[0]);
printf ("data[1] address %p and value %08" PRIx32 "\n\n", &data[1], data[1]);
/* Make a pointer to the first byte of the array */
uint8_t *u8ptr = (uint8_t *)data;
for (size_t i = 0; i < 8; i++)
{
printf ("u8ptr[%zd] address %p and value %02" PRIx8 "\n",
i, &u8ptr[i], u8ptr[i]);
printf ("u8ptr+%zd address %p and value %02" PRIx8 "\n\n",
i, u8ptr + i, *(u8ptr + i));
}
|

Bug Warning
It is critical to understand that C does not explicitly store the length of an array anywhere, so
there is no way to learn this information for a pointer to an arbitrary array. Consider the
data and ptr variables as declared below. By examining this code, we can determine that the
data array takes up 16 bytes and consists of four consecutive 32-bit values; i.e., this portion
of source code makes it clear that the length of the array is four.
1 2 3 4 5 6 7 | uint32_t data[4]; // an array of four 4-byte ints
uint32_t *ptr = data;
printf ("sizeof(data) = %zd\n", sizeof (data)); // 16, NOT 4
printf ("sizeof(ptr) = %zd\n", sizeof (ptr)); // 8, NOT 4
printf ("number of elemenst = %zd\n", sizeof (data) / sizeof (uint32_t)); // SUCCESS!
|
A very common mistake is to try to use sizeof() as shown on lines 4 and 5. With one exception
(shown on line 7), sizeof() cannot be used to determine the length of an array.
Recall that sizeof() returns the number of bytes for a variable; it is not aware of the
subdivision of those bytes into an array of consecutive elements. As such, the sizeof(data) on
line 4 returns 16, which is the total number of bytes for the array. Similarly, the sizeof(ptr)
on line 5 returns 8, which is the size of a pointer (i.e., an address) on a 64-bit CPU
architecture. Neither of these return the number of elements in the array.
Line 7 is successful because we know the total amount of space for data (sizeof(data) =
16 bytes) and we know data is an array of uint32_t items (sizeof(uint32_t) = 4 bytes for
each item). Having both of these pieces of information allows us to perform this calculation. We
cannot perform this same calculation using sizeof(ptr), however. That is, if we are given a
pointer (such as ptr) and we know that it is pointing to an array of uint32_t items, we
cannot determine the length of the array. The problem is that ptr technically does not point to an
array; rather, it points only to the first element of the array. There is no way to attach the
additional information of the size of the array to the pointer.
This point becomes really important later, when we discuss the relationship of arrays and functions.
Specifically, arrays cannot be directly passed as an argument to a function call. Rather, arrays
are always passed as pointers. Because of this fact, the length of the array must be passed
explicitly as a separate parameter. The simplest example of this is the parameter list of
main(), which consists of an array (argv) and its array length (argc).
1 2 3 4 5 | int
main (int argc, char *argv[])
{
...
}
|
10.4.1. Two-dimensional Arrays¶
One side effect of C not storing array lengths is the complexity of working with multi-dimensional
arrays. Consider Code Listing A.14 as an example. Line 6 declares an array that
contains two rows of three columns each. When declaring data on this line, the 3 must be
specified within the brackets to indicate the number of columns per row. That is, this declaration
could not be written as data[][], even with the explicit initialization on the right side of the line.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | /* Code Listing A.14:
Traversing through a two-dimensional array
*/
/* Instantiate a2-d array and print its starting address */
uint32_t data[][3] = { { 1, 2, 3 }, { 4, 5, 6 } };
printf ("data starts at %p\n\n", data);
/* Make u32ptr point to data, but observe that this causes a
compiler warning; the warning can be fixed by casting data
((uint32_t *)data) or using one layer of brackets (data[0]) */
uint32_t *u32ptr = data;
/* Loop through the elements, observing that array bracket
notation and pointer arithmetic behave identically */
for (size_t i = 0; i < 2; i++)
for (size_t j = 0; j < 3; j++)
{
printf ("data[%zd][%zd] address %p, value %08" PRIx32 "\n",
i, j, &data[i][j], data[i][j]);
printf ("u32ptr[%zd] address %p, value %08" PRIx32 "\n",
i * 3 + j, &u32ptr[i * 3 + j], u32ptr[i * 3 + j]);
printf ("u32ptr+%zd address %p, value %08" PRIx32 "\n\n",
i * 3 + j, u32ptr + (i*3+j), *(u32ptr +(i*3+j)));
}
|
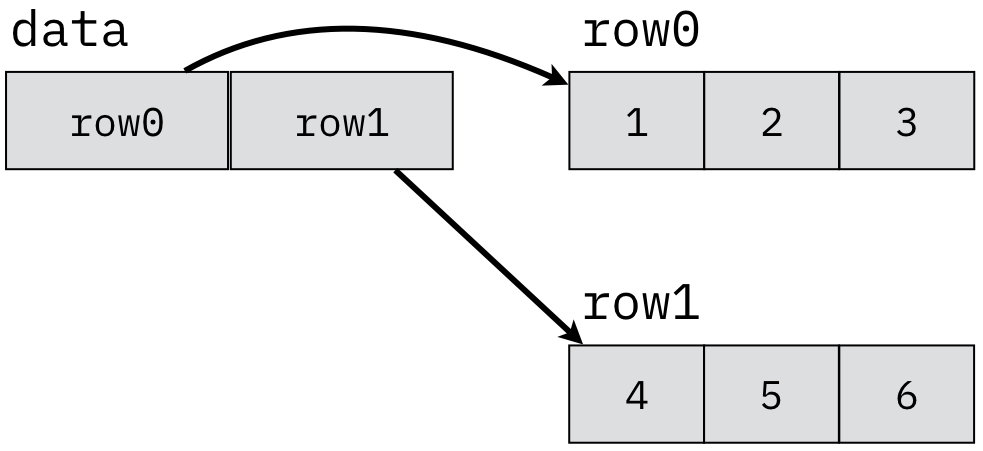
Figure 10.4.2: Creating a virtual 2-d array with an array of pointers
The rest of Code Listing A.14 is modeled off of the structure of Code Listing A.12. As in that example, there is a u32ptr that is set to point to the array (line 12).
Based on the declaration, though, u32ptr is a pointer to a uint32_t. Because of this
declaration, it can be used as a one-dimensional array, but not as a two dimensional array. That is
not a problem in this case, because C stores arrays in row-major order; in this order, the
first element of the second row is placed immediately after the last element of the first row. That
is, data[1][0] (the same as u32ptr[3]) immediately follows data[0][2] (the same as
u32ptr[2]). Thus, a one-dimensional array pointer like u32ptr can navigate the two-dimensional
structure by calculating its index as i * 3 + j (row times columns/row, plus the column number
of the current row). This requires, of course, knowledge of the number of columns per row. When
two-dimensional arrays are passed as arguments to functions, this additional information must be
passed explicitly as separate parameters.
Code Listing A.15 demonstrates a common variation on two-dimensional arrays. In this
case, data is not declared as a two-dimensional array; rather, it is one-dimensional array of two
pointers. Its initialization in line 10 provides those two pointers: the addresses of the two arrays
row0 and row1. Unlike the declaration structure of Code Listing A.14, this
version does not guarantee that the elements can all be accessed in row-major order. The row0
and row1 arrays are not guaranteed to be in any particular order in memory; consequently, we
cannot say that row1[0] immediately follows row0[2]. Figure 10.4.2
illustrates the pointer structure of this declaration.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | /* Code Listing A.15:
Two-dimensional arrays as arrays of pointers
*/
/* Instantiate the rows separate */
uint32_t row0[] = { 1, 2, 3 };
uint32_t row1[] = { 4, 5, 6 };
/* data is an array of two pointers, NOT a 2-d array */
uint32_t *data[] = { row0, row1 };
/* But we can still treat data as a 2-d array */
for (size_t i = 0; i < 2; i++)
{
printf ("data[%zd] = %p\n", i, data[i]);
for (size_t j = 0; j < 3; j++)
printf ("&data[%zd][%zd] = %d <%p>\n", i, j, data[i][j], &data[i][j]);
}
|
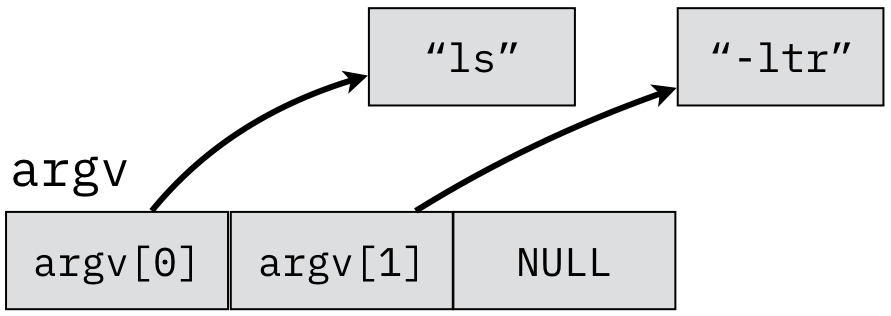
Figure 10.4.3: The argv array of command-line arguments is an array of pointers
Despite this more complex inner structure, lines 13 – 18 illustrate that the array can still be
treated like a two-dimensional array for accessing elements. This code works as an artifact of an
earlier point in this section: pointers can be dereferenced using bracket notation. In this case,
data is declared as an array of uint32_t* elements, so data[0] is a pointer storing the
address of row0. Accessing data[0][1], then, is the same as accessing row0[1] because of
the pointer dereferencing.
Figure 10.4.3 illustrates a familiar example for this same concept. Consider the
command line to list files as "ls -ltr". In this case, argv[0] is "ls" and argv[1]
is "-ltr" internal in the process that runs this program. Since the parameter is declared char
*argv[] (i.e., an array of pointers to chars), we can see that each element is a pointer to a
string.
10.4.2. Structs and Packing¶
Elements in an array are, by definition, all of the same type. Given the declaration int
data[5], we know that the five elements are ints and these elements occupy a single block of
consecutive bytes in memory. The total size of this block is exactly the number of elements (5)
times the size of each element (an int is typically 4 bytes). To distinguish the elements within an
array, each element has a unique index that can be used in the bracket notation. As described
previously, bracket notation is semantically equivalent to calculating the offset to a memory
location using pointer arithmetic. That is, data[2] is equivalent to *(data + 2), and both
notations refer to the calculation of a particular offset from the starting address of data.
Like arrays, structs are used to create a chunk of contiguous data in memory, but with two
differences. First, the fields (rather than elements) of a struct are accessed with a name,
rather than an index. Second, the fields in a struct do not have to adhere to the same type.
Code Listing A.16 illustrates both of these facts with a struct declaration for
keeping track of time records. It is important to emphasize that lines 5 – 8 only define the
structure of one of these structs (similar to defining a class in an object-oriented language like
Java), rather than creating an instance of a struct in memory. In contrast, line 13 creates an
instance as a local variable, with lines 14 and 15 initializing the fields of this struct. This
declaration and initialization could be done on a single line, similar to initializing an array;
line 13 could be extended to read ts = { 100, 258.9275 }, though this style requires knowing the
specific order of elements in the struct.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | /* Code Listing A.16:
A struct declaration to keep track of a time record
*/
struct timestamp {
int date; // days since a given start data
double time; // seconds since midnight of the current day
};
int
main (void)
{
struct timestamp ts;
ts.date = 100;
ts.time = 258.9275;
printf ("Time stamp: %d:%lf\n", ts.date, ts.time);
return 0;
}
|
In the computer systems field, this view of structs as objects without methods is not necessarily
sufficient. In particular, when two different machines are exchanging data, the two systems need to
agree on the layout and interpretation of the bytes without the struct. This agreement is not
necessarily guaranteed, even if the same source code is used. Different compilers may arrange the
fields in different orders, and the CPU may interpret multi-byte sequences differently due to
endianness issues. Code Listing A.17 demonstrates how to perform introspection into the
layout of a struct in code.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | /* Code Listing A.17:
Exploring the size and layout of a struct
*/
struct alternating {
uint8_t a;
uint32_t b;
uint16_t c;
uint8_t d;
};
struct alternating alt = { 1, 2, 3, 4 };
printf ("sizeof(alt) = %zd\n", sizeof (alt));
printf ("alt.a at %p, value %" PRId8 "\n", &alt.a, alt.a);
printf ("alt.b at %p, value %" PRId32 "\n", &alt.b, alt.b);
printf ("alt.c at %p, value %" PRId16 "\n", &alt.c, alt.c);
printf ("alt.d at %p, value %" PRId8 "\n", &alt.d, alt.d);
|
Line 14 prints the size of one struct alternating instance, alt. Reading lines 5 – 10
suggests that line 14 will indicate that the size of alt is 8 bytes (4 for a, 1 for b, 2
for c, and 1 for d). This intuition is wrong for typical compilers and modern hardware.
Using both the clang and gcc compilers on an x86 architecture, the compiled code indicates
that alt is 12 bytes in size. The specific layout of the memory for alt is shown in Table A.4.
To be precise, the address of alt is the address of the byte on the left,
containing the value 0x01; the memory addresses increase from left to right in this table. As
x86 is a little-endian architecture, the bytes of the multi-byte fields b and c are
structured with the least-significant byte on the left (indicating a lower address offset within the
struct).
a |
?? |
?? |
?? |
b |
c |
d |
?? |
||||
|---|---|---|---|---|---|---|---|---|---|---|---|
01 |
?? |
?? |
?? |
02 |
00 |
00 |
00 |
03 |
00 |
04 |
?? |
Table A.4: The layout of an unpacked struct with padding bytes
The fields shown as ?? in Table A.4 indicate additional bytes of padding. The
compiler injects this padding because of how memory is physically access by the CPU. The compiler
can also (but does not in this case, re-order the fields if necessary. Generally speaking, bytes
that are stored in the same memory word can be accessed in a single CPU cycle. A memory word
is a sequence of four consecutive bytes, but these bytes need to begin at a word boundary
(an address that is evenly divisible by four). If we assume that alt begins at address
0x7ffe000027c0 (which is a word boundary), the three bytes of padding just after the a
ensure that b starts at another word boundary, 0x7ffe000027c4. If b, instead, began
immediately after a at address 0x7ffe000027c1, then the contents of b would span two
distinct memory words. As a result, accessing b would now require two CPU cycles instead of just
one. This additional cycle might sound trivial (since there are billions of cycles per second), but
the cumulative effect over all programs would be significant. The padding after the d rounds up the
size of the struct to be an exact multiple of three words. This padding helps ensure other data
on the stack around the alt variable also begin at word boundaries.
But what if the code needs to adhere to a specification that the struct alternating cannot have
padding? That is, each struct instance needs to be exactly eight bytes, interpreted in the order
defined by the struct. In this case, the struct needs to be declared as packed,
meaning that there is no padding or re-ordering allowed. To declare the struct as packed, the
only change is to modify the first line of Code Listing A.17 with the packed attribute:
struct __attribute__((__packed__)) alternating {

Note
Computer systems frequently take advantage of very compact data representations, particular in the
networking domain. Bit masks, for instance, use the individual bits within a byte to represent
distinct pieces of information. Within the struct declaration, the individual field names are
append with :n to indicate that the field occupies n bits. Packed structs also help with
this data compression by ensuring that there is no padding added. Consider the following example:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | struct __attribute__((__packed__)) bits {
unsigned type:2; // can be 0, 1, 2, or 3
unsigned urgent:1; // can be true (1) or false (0)
unsigned length:7; // anywhere from 0 to 31
};
struct bits data;
memset (&data, 0, sizeof (data)); // ensure all bits init to 0
data.type = 3;
data.urgent = false;
data.length = 27;
printf ("Size of data is %zd\n", sizeof (data));
/* Cast the address of data to a uint16_t* and dereference it */
printf ("data as a hex int is %04" PRIx16 "\n", *((uint16_t*) &data));
|
The declaration of struct bits indicates that one instance requires 10 bits. Since we cannot
actually allocate data at this bit level, this instance would be padded to make it exactly two
bytes (16 bits) in size. Among those 16 bits, the C standard does not specify an exact order. The
fields should only be accessed through their names, as shown in line 9 – 11. It is possible,
however, to determine the layout on a particular system through trial and error. The printf()
call on lines 15 and 16 reveal that one possible layout is as follows:
| First byte | Second byte | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| [unnamed and unused] | length |
urg |
type |
||||||||||||
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
0 |
1 |
1 |
0 |
1 |
1 |
0 |
0 |
d |
b |
||||||||||||
Based on this illustration, the seven bits of the length field spans the two bytes, whereas
urgent and type both reside in the second byte. The bottom line shows the hexadecimal
representation of four bits at a time. Printing the full value, as on lines 15 and 16, produces the
output 0x00db.
10.4.3. Enums and Type Definitions¶
From the programmer’s perspective, C’s built-in types and structs are low-level primitives that
make it difficult to read and understand the code. For instance, in the case of structs, the
type is always the full name consisting of struct and the identifier following it. In the case
of alt from Code Listing A.17, its type is struct alternating; its type is not
struct, nor is its type alternating. Copying the word struct around gets tedious and it
detracts from the readability. As for the primitive types, an int indicates an integer value, but
what if there are only certain integers that are valid? For instance, consider a variable that is
used to keep track of the day of the week (Sunday through Saturday) as an integer (Sunday is 1,
Saturday is 7). Referring to day 37 might lead to an unpredictable error.
To start with the latter problem, the solution is to define an enumerated type, or enum. An
enum is a custom integer type that allows the programmer to use names instead of numeric
constants. Code Listing A.18 declares an enum for the days of the week as
previously described. In the declaration, the values in the enum are automatically incremented.
By setting SUN = 1 (instead of allowing the default starting value of 0), MON would be 2,
TUE would be 3, and so on. The advantage of the enum is that we can use these meaningful
names (MON, TUE, WED, …) instead of memorizing numeric values. We can also declare
variables using the enum type as shown on line 6.
1 2 3 4 5 6 7 | /* Code Listing A.18:
Declaring the days of the week as an enumerated type
*/
enum days { SUN = 1, MON, TUE, WED, THU, FRI, SAT };
enum days today = WED;
printf ("Tomorrow is %d\n", today + 1);
|
To be clear, enums are a syntactical mechanism of convenience, not security. Internally, an
enum is just an int, and C does not perform any bounds checking to ensure that the values of
an enum variable (such as today) match the names or the range in the definition. Line 6 could
initialize today to be 37, or line 7 could be changed to use today - 452; either would be allowed,
as today is ultimately just an int variable.
The enum keyword has the same problem as the struct keyword, in that it must be included in
the type name and passed around throughout the code. In Code Listing A.18, the type of
the today variable is enum days, not enum or days. To make the code more readable for
both enums and structs, we can declare a new custom type name with the typedef
keyword. Code Listing A.19 uses typedef on the enum from A.18 and
the struct from A.17.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | /* Code Listing A.19:
Simplifying enum and struct type names with a typedef
*/
typedef enum days { SUN = 1, MON, TUE, WED, THU, FRI, SAT } day_t;
day_t today = WED;
typedef struct alternating {
uint8_t a;
uint32_t b;
uint16_t c;
uint8_t d;
} alt_t;
alt_t alt = { 1, 2, 3, 4 };
|
The general structure for declaring a new type is typedef [existing type] [new type name];. By
convention, the new type name typically ends with _t to indicate that this is a type. Observe
that there are many such type definitions in the C standard library. For instance, the size_t
type is defined (indirectly, as there are several chained type definitions involved) in the
ctype.h header as shown below. The advantage of using the type definition is that it provides
additional semantics. A variable declared as a size_t is not just being used as an integer, but
as the size of something.
typedef int32_t size_t;
One common problem with type definitions for structs,`in particular, is when there are circular
dependencies. Consider Code Listing A.20 that defines a person_t type and an
age_t type. In this application, each person (person_t) has a unique name and age, but each
age_t has and unique year and pointers to up to 5 people. In other words, the person_t
definition needs to know about the age_t type, while the age_t definition needs to know
about the person_t type. The problem is that the definition of person_t (lines 7 – 10) comes
before the C compiler has learned about the age_t type (line 15); the C compiler cannot look
ahead, so using age_t on line 9 would be a compiler error.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | /* Code Listing A.20:
Defining two structs with a circular definition
*/
struct age; // dummy struct definition
typedef struct person {
char *name;
struct age *age;
} person_t;
typedef struct age {
int year;
person_t *people[5];
} age_t;
|
The solution is to use a dummy struct definition on line 5 that matches the name on line 12. (It
is vital that the name of both struct types match.) By structuring the code this way, the
compiler is able to correctly link the type of the age field within person_t as a pointer to an
age_t instance later. Once this is done, the circular definition can be ignored, as shown in
Code Listing A.21. The person_t instance is able to set its age field to the
address of an age_t instance without causing a compiler error or warning.
1 2 3 4 5 6 7 8 9 10 11 12 | /* Code Listing A.21:
When using the structs, the circular definition is not visible
*/
person_t person;
age_t age;
person.name = "Gustavo";
person.age = &age;
age.year = 35;
age.people[0] = &person;
|