10.9. Files¶
The idea of organizing and storing data as a file is one of the oldest abstractions in computing, with references to files dating back to the earliest computers in the 1940s. From the perspective of C and the UNIX OS tradition, a file is just a sequence of bytes. Chapter 2 explores the implications of this definition in further detail, such as the fact that not all files exist on persistent storage devices and not all files have names. In this Appendix, for simplicity, we will adopt the conventional interpretation of a file stored on a device, such as a hard drive or a USB-attached device.
10.9.1. File Permissions and Ownership¶
When a file is stored, there is a certain amount of information—called metadata—that is stored alongside the file’s contents. Metadata is stored in a data structure called an inode, as discussed in Chapter 2. The inode contains a number of fields, one of which is the files permission mode. The permission mode indicates which actions (read, write, or execute) can be performed on a file by a particular user. These permission modes are commonly written as three octal values to specify permissions for the user (the owner of the file), the group (a pre-defined set of users), or others (everyone else). For each octal value, 4 (binary 100) indicates read permission, 2 (010) is write, and 1 (001) is execute. Setting one of these bits to 0 removes that permission.

C library functions – <sys/stat.h>
int chmod(const char *path, mode_t mode);- Change the permissions associated with a file.
int fchmod(int fildes, mode_t mode);- Change the permissions associated with an open file given its file descriptor.
The chmod() and fchmod() functions, which can only be used by the owner of a particular
file, provide an interface to change the permissions on a file. The first argument specifies which
file, either by the standard file name (path) or using a file descriptor (filedes). The mode
argument is the new permission bit mask to apply. Although the mode_t type is just an integer
(e.g., 493), these numbers are written in their octal equivalent (0755). (The leading 0 is
required to indicate octal format.) Among the three digits, the first applies to the user, the
second to the group, and the third to others.
1 2 3 4 5 6 7 8 9 10 11 12 13 | /* Code Listing A.58:
Changing two files' permissions within a program
*/
/* Everyone has read access, user also has write */
chmod ("data.txt", 0644);
/* User and group can execute the Python script, and the user can
modify (write) it; others have no access */
chmod ("script.py", 0750);
/* Restrict access to a private directory */
chmod ("/home/csf/private_files", 0700);
|
Code Listing A.58 changes the permissions on three files using the chmod()
function. The bit mask on line 6 (0644) indicates that the user will have read and write
permission (applying the bit-wise OR operator, 4 | 2 = 6), while the group and other have only
read permission. Line 10 gives the user all permissions (4 | 2 | 1 = 7, meaning read, write, and
execute), whereas the group only has read and execute (4 | 1 = 5). Line 13 changes the
permission on a directory—a special file that “contains” other files (explained below).
Directories in the UNIX tradition are the equivalent of folders in the Windows family of operating
systems. The permissions here give the user full access to the directory, but the group and others
are blocked out. These operations can also be performed on the command line as follows (note that
the chmod utility is a C program that calls chmod() internally!). The ls -ld command
displays the permissions at the first part of the file, in a format rwxrwxrwx for the three
octal values (- indicates that permission is not set).
$ chmod 644 data.txt
$ chmod 750 script.py
$ chmod 700 /home/csf/private_files
$ ls -ld data.txt script.py /home/csf/private
-rw-r--r-- 1 csf staff 8528 Jul 31 23:20 data.txt
-rwxr-x--- 1 csf staff 440 Jul 31 23:20 script.py
drwx------ 11 csf staff 352 Jul 31 23:20 /home/csf/private

Note
The permission bits—particularly read and execute—are not as intuitive as their names suggest. For instance, why is the read bit required to run the script.py Python script? As a piece of code, the goal is to run—i.e., execute—it. Similarly, what does it mean to “execute” a directory? The interpretation of these bits requires considering the type of file in a greater context.
For normal files (i.e., non-directories), the read bit indicates that a running process can open the
file and copy its contents into memory. In the case of scripting languages like Python, it is
important to understand that the process that is running is not executing the script.py code.
It can’t, because to “execute” code means that the CPU is performing machine-language instructions;
Python code is not machine language, because it is not compiled. Rather, the process is running the
Python interpreter (typically stored in a location like /usr/bin/python). The read permission
bit gives the Python interpreter access to read in script.py as text data. The interpreter then
simulates the execution of the program. For performance reasons, the interpreter might compile
parts of the script into machine language using just-in-time compilation, but that is not
necessary.
So if Python only needs to read the file, what is the purpose of setting the execute bit on
script.py? In truth—and somewhat ironically—the execute bit does not indicate that
script.py can be executed. The execute bit on files declares that the file should be found as
an executable within the $PATH environment variable—a list of locations to search for
executables—that the shell (bash) uses. When you type a command, bash searches through the
locations listed in the $PATH for the first match of that command name that has the execute bit
set. To start the process, bash looks into the file contents to look at the first line of the
program. In the case of scripts like script.py, the first line contains a shebang operator
that indicates the location of the interpreter that is needed:
#!/usr/bin/python
Consequently, executing a Python script requires the execute bit to add it to the $PATH that is
searched, but requires the read bit for the program to actually run.
The execute bit on directories is also frequently misunderstood, primarily because the bit is misnamed for directories. A directory is not a piece of code that can be run (executed). Instead, reading a directory is defined as listing its contents, whereas the execute bit allows the user to enter or pass through the directory. For instance, consider the following file name (storing a cryptographic key that can be used to log into a remote email service), based on the permissions above:
/home/csf/private/keys/email.id_rsa
Code Listing A.58 set 0700 permissions for the /home/csf/private. The read bit
allows the user to list the file contents (using the ls command, for instance). However,
accessing those files or the subdirectories requires the execute bit. Since the group and others
have no permissions, no one else can get access to the keys subdirectory, because doing so
requires passing through private. Since the read and execute actions are distinct, the bits can
be set independently. Setting a directory to 0444 would allow everyone to see the names of
files in the directory, but no one could access any of them or access any subdirectories. On the
other hand, setting the directory to 0111 would give everyone access to the files and
subdirectories…if they already knew the name; these permissions would not allow anyone to list
the directory contents to see the names of the files.
For completeness, writing to a directory means adding or removing files. When you save a new file into a directory, you are writing to the directory by adding an entry. When you delete a file, you are also writing by removing the entry. It is important to note that these operations are changes to the directory, not the file itself. To be precise, this means that you do not have to own a file in order to delete it. When you are deleting a file, you are not writing to it; you are writing to the directory. As such, if you have data that is important and should never be deleted, you should not place it in a directory that others can write to.
The access() function provides an interface to check a file’s permissions before trying to
access it. As with the chmod() function, the first parameter specifies the name of the file
being checked. The mode parameter is not the same as the mode_t type used above, because
access() is only checking the permissions for the current user. Furthermore, access() can
check more than just the standard read, write, and execute bits, so this mode does not follow the
same octal structure.
C library functions – <unistd.h>
int access(const char *path, int mode);- Check for permission to access the specified file.
Code Listing A.59 uses access() to determine if a file is readable. Intuitively,
the R_OK, W_OK, and X_OK arguments (which can be successfully combined with bit-wise OR)
check for read, write, and execute permissions. The F_OK argument could be used to check just if
the file exists, regardless of the other access permissions. Different systems also support
additional values that could allow the user to check if a file can be deleted, if the user can
change its permissions, and so forth; these options are system-specific, though, and are not widely used.
The unistd.h header file provides additional functions that are relevant to the discussion of
access permissions. The chown() and fchown() functions provide interfaces to change which
user or group is considered the file’s owner. These functions are generally restricted in certain
ways; clearly, it would not be advisable to allow a random user to take over another’s files by
changing their ownership. Some systems allow users to run these functions only on files that they
own, whereas others restrict access to these functions to system adminstrators.
C library functions – <unistd.h>
int chown(const char *path, uid_t owner, gid_t group);- Change the ownership of a file path.
int fchown(int fildes, uid_t owner, gid_t group);- Change the ownership of a file specified by a file descriptor.
The getuid(), geteuid(), getgid(), and getegid() functions are not about files, per se, but they are relevant to the current discussion. These functions get information about the current process that is executing. Whenever you run a program, you create a process; the process inherits a specified user ID and group ID that control the process’s access. Consequently, when the previous examples referred to checking the “user’s” access to a file, this check is based on the user ID associated with the process executing this code.
C library functions – <unistd.h>
uid_t getuid(void);- Gets the real user ID of the calling process.
uid_t geteuid(void);- Gets the effective user ID of the calling process.
gid_t getgid(void);- Gets the real group ID of the calling process.
gid_t getegid(void);- Gets the effective group ID of the calling process.
The functions below make a distinction between the real user and the effective user.
(All of the points here also apply to the real group and effective group; we only mention the user
for brevity.) The real user is the ID of the account that initiated the creation of the process,
whereas the effective user is the one attached to the process as it runs; these IDs are typically
the same, but they do not have to be. Functions that check permissions, such as access(),
generally use the effective user ID, though there are exceptions where the real user ID can also
influence access decisions.
As an example of the distinction between the real and effective user, consider an executable file
with the SETUID bit set (see Chapter 2); this bit sets the process’s effective user ID to be the
user ID of the executable file’s owner, rather than the user who ran the command. One common use of
this is to have the SETUID bit set on a file owned by the administrative (root) account; the
process that runs will then have full access to the system, as it is running as root rather than a
restricted user account. This technique is how a login program can run to check a user’s password
against the full password list, but the user does not have direct access to the password file.
Another example of the real vs. user distinction can be manually created with the su command.
Contrary to a common belief, su does not necessarily mean “super user” (a common term for
root); rather, su means substitute user. Running a command with su will change the
effective user ID of the process, even if the SETUID bit is not set. For example, the following
command line would run the ls command based on the csf username [1], rather than the
default user typing the command. Consequently, the permission checks (to determine if the process is
allowed to list the current directory’s file contents) are based on the csf username, not the
actual user.
$ su csf ls -ltr
10.9.2. Persistent Storage¶
Chapter 2 covers most of the details about working with files, such as reading from and writing to them. That section, however, uses a broader definition of files than this part of the Appendix. Here, we are focusing just on files in the traditional, common sense; i.e., those that are persistently stored on a device such as a hard drive. The storage techniques used for these files raise particular issues that are beneficial to understand for systems programming.
The first issue, which we have already discussed, is that of metadata. When a file is stored, the metadata is stored in an inode structure. It is important to realize two facts: 1) the inode—not the contents—actually defines the file, and 2) the inode is stored separately from the contents. In other words, the inode—which is stored on the device—contains information to identify other blocks of data on the device that store the file’s contents. When a file is modified, the new contents may be written to the existing blocks, but maybe not. The new contents may be written to different blocks, and the inode is simply changed to point to these new blocks; the old content blocks are still present on the device, the inode just doesn’t point to them anymore. Similarly, when a file is deleted, the content blocks are not necessarily destroyed; just the inode is deleted (in fact, that’s not even entirely true, as we will describe in relation to directories).
When a file is in use (such as when you are editing a source code file in a text editor), all of the
file contents exist in memory. Generally speaking, you are not directly interfacing with the file
stored on disk; compared to accessing a copy in memory, accessing the stored copy would be
horrendously slow. As you modify the file, the version in memory and the original stored copy become
different. The unistd.h header file defines three key functions for fixing this. The ftruncate()
and trunctate() functions are used to resize [2] the file’s in-memory representation; for
instance, if you delete a large chunk of your program’s code, the text editor may run truncate()
to reduce the memory allocated for it.
These changes are not automatically propagated to the inode stored on the device. This update
typically (the details depend on the OS and the file system in use) only occurs when the file is
closed or when the process calls fsync(). The fsync() function—which is run when you save a
file—writes the contents to the storage device and updates the stored inode accordingly.
C library functions – <unistd.h>
int fsync(int fildes);- Synchronize the in-memory file contents with persistent storage.
int ftruncate(int fildes, off_t length);- Truncate or extend a file size to the specified length.
int truncate(const char *path, off_t length);- Truncate or extend a file size to the specified length.
10.9.3. Directories and Links¶
It is likely that the reader is familiar with the term directory as it is used in relation to files. When working at the systems level, it helps to have a more in-depth understanding than the basic idea of directories (or folders) as places where files are stored. Specifically, it is important to note that files are not actually stored in directories. As noted above, a file is defined by an inode, as persistent data structure that contains the file’s metadata and pointers to the file’s contents. The location of the inode on the device is determined by the OS and the file system. The inode number is a persistent location identifier that tells the OS where to find the inode on the device.
From this perspective of inodes, one may observe that we have not mentioned the concept of file names. The reason for this is that file names do not, in fact, identify files. When we are working at the level of inodes, files do not have names. Names are introduced by the concept of directories. A directory is simply a special type of file that contains a mapping between a string (name) and the corresponding inode. Figure 10.9.7 illustrates this concept for two directories and two regular files.
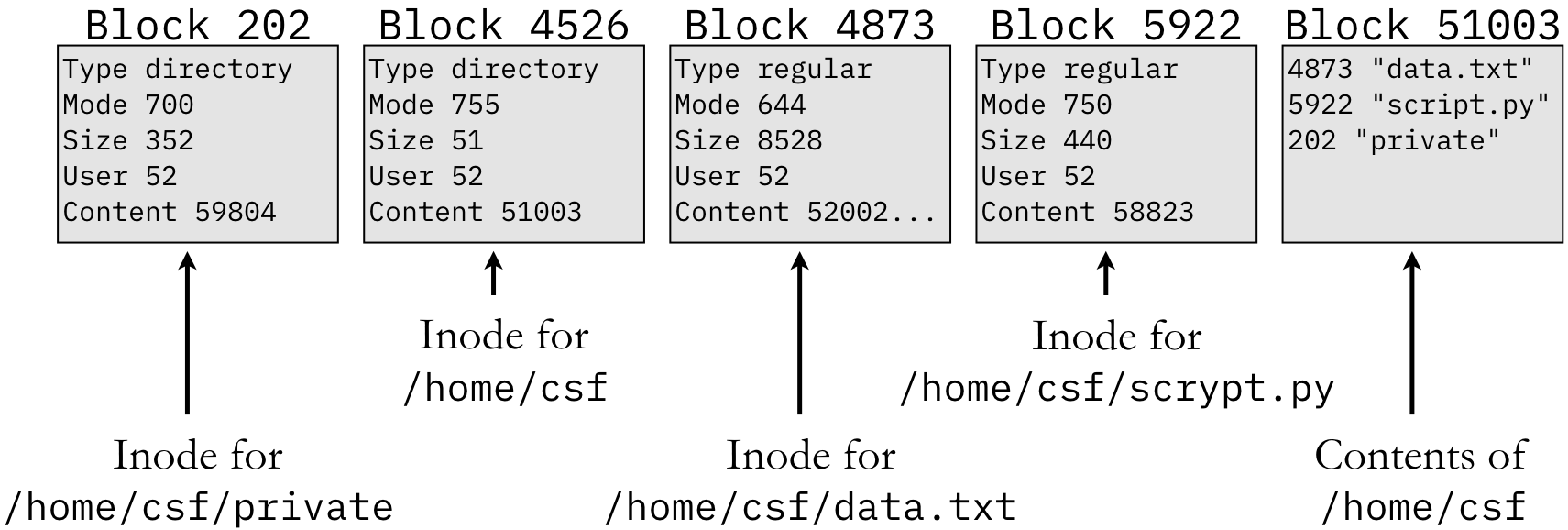
Figure 10.9.7: Sample blocks containing inodes and a directory’s contents
To start, assume that we are examining the directory /home/csf. Since directories are files
(just a special type of file), this directory has an inode and an inode number. In Figure 10.9.7, the inode number for /home/csf is 4526, which identifies the block [3]
of that number. That inode indicates that the file is a directory with permissions set to
0755, etc. The Content field indicates the block number containing the directory’s contents.
By examining the contents in block 51003 (the block number and the inode number are the same), we
can see that this directory contains three files: data.txt, script.py, and private. The
directory indicates that the string "data.txt" (or the full path /home/csf/data.txt) refers
to inode 4873. This inode indicates that the file is a regular file and its contents begin at block
52002. (For historical reasons, blocks are 512 bytes in size; if the file exceeds 512 bytes, it will
require multiple content blocks.) Similarly, blocks 5922 and 202 contain the inodes for script.py
and private, respectively; the inode for the latter indicates that private is a directory.
Readers who have become comfortable with working on the command line are likely to have heard
references to “being in” or “changing to” a directory. These phrases refer to examining or changing
the current process’s current working directory, the default location that the process will
look for files. Note that, when you are working on the command line, you are always running a
process: the shell (typically bash). The cd command tells the bash process to change its
current working directory. When you run a separate program by typing a command, bash creates a new
process, and that new process inherits bash’s current working directory; this new process could
change its current working directory with the chdir() and fchdir() functions.
C library functions – <unistd.h>
int chdir(const char *path);- Change the current working directory based on the provided
path. int fchdir(int fd);- Change to the directory given as the open file descriptor
fd.
At this point, we have established that directories do not contain files or inodes; they just map a
string to an inode number. Similarly, the chdir() function can change which directory the
process will look in by default. Based on this understanding, we can now distinguish between
hard links and symbolic links. A hard link is a
directory reference to an inode. In Figure 10.9.7, block 51003 contains an
entry for data.txt that links to inode 4873. Within inode 4873, there is a field that counts the
number of such links; so 4873’s link count would be at least one. This figure did not show the
contents of the /home/csf/private directory, but assume that it contains an entry for a file
named copy.txt that also maps to inode 4873; i.e., there is a /home/csf/private/copy.txt file,
and it points to the same inode as /home/csf/data.txt. In other words, the full path names
/home/csf/data.txt and /home/csf/private/copy.txt are both hard links to the same inode and
the inode’s reference count must be at least two. The effect of this hard link is that these two
files are the same; changing the contents of one will change the other. Such hard links are created
with the link() function.
C library functions – <unistd.h>
int link(const char *path1, const char *path2);- Make
path2a hard link with the same attributes aspath1. int symlink(const char *path1, const char *path2);- Make
path2a symbolic link to the file identified bypath1. int unlink(const char *path);- Remove a link to a file specified by the given
path.
Unlike changes to a file, the unlink() function only removes a single such link by deleting the
entry from the relevant directory. That is, calling unlink() on /home/csf/private/copy.txt
would remove the entry for copy.txt from the /home/csf/private directory. The file contents
could still be accessed using the /home/csf/data.txt path name. As long as there is at least one
reference to the file contents, the file cannot actually be “deleted” in the casual sense. In fact,
even when the reference count for an inode drops to 0, the contents are not necessarily destroyed.
Instead, the blocks containing the inode and the file contents are marked as available for future
use. Neither is truly destroyed until they are overwritten when they are assigned to a different
file in the future.
In contrast to hard links, a symbolic link (also known as a shortcut in the Windows family of OS)
is a distinct file with its own inode. The inode’s type field would indicate that it is a symbolic
link (or symlink for short) rather than a regular file. The inode’s Content would point to a content
block just like a regular file; however, the contents would be the path name that the symbolic link
points to. To illustrate the difference, consider the following command lines, which start with an
original C source file called hello.c:
$ ln hello.c link.c
$ ln -s hello.c symlink.c
$ ls -li hello.c link.c symlink.c
12909398185 -rw-r--r-- 2 csf staff 74 Feb 23 17:09 hello.c
12909398185 -rw-r--r-- 2 csf staff 74 Feb 23 17:09 link.c
12909398210 lrwxr-xr-x 1 csf staff 7 Feb 23 17:10 symlink.c -> hello.c
The first ln command uses link() to make link.c a hard link to the contents of hello.c.
The -s flag on the second ln command calls symlink() instead, making symlink.c a
symbolic link to hello.c; that is, symlink.c is a distinct special file whose contents are
the literal string "hello.c" to indicate the target of the link. (Note that the symbolic link
does not actually check for—or have any knowledge of—the existence of hello.c itself.) The ls
-li command shows metadata about the three files. The first field on each line is the respective
inode number (produced by the -i flag). Since hello.c and link.c are hard links to the
same contents, their inode is the same. On the other hand, symlink.c is a separate file with a
distinct inode number.
One of the key differences between hard links and symbolic links can be observed through deletion.
Hard links are bound to the actual file contents, whereas symbolic links are bound to the name. If
the target of a symbolic link (hello.c in this case) is deleted (the rm command calls
unlink() on the hello.c file name) and recreated with the same name, accessing the symbolic
link will reflect the new contents; accessing the other hard link will get the old contents. The
original contents will only be deleted when all hard links are removed.
$ rm hello.c
$ cat link.c
[original contents here...omitted for brevity]
$ cat symlink.c
cat: symlink.c: No such file or directory
$ echo "goodbye" > hello.c
$ cat link.c
[original contents here...omitted for brevity]
$ cat symlink.c
goodbye
10.9.4. Advisory Locks¶
When concurrent software is working with files, there is the danger that multiple processes or threads might try to access or modify an existing file at the same time. This situation would allow one process or thread to change the file’s contents in ways that can cause errors in the other process or thread. Different OS and file systems provide a variety of mechanisms to prevent this from happening; as these approaches can vary between systems, it can be difficult to rely on them for cross-platform software. One mechanism that generally has cross-platform support is the use of advisory locks, which provide a mechanism for cooperating processes to try to avoid this situation. In essence, an advisory lock allows a process to check if another process has already locked the file; if so, the new process can wait until the first process is finished. As the name implies, though, these are advisory in nature; the new process can still proceed regardless of the first process’s claim.
C library functions – <sys/file.h>
int flock(int fd, int operation);- Apply or remove an advisory lock on an open file.
The flock() function provides one mechanism to create an advisory lock on a file. Unlike some of
the previous functions we have described, flock() only works with file descriptors (see Chapter
2), not path names. That is, the process must have access to the file and must have already
successfully opened it. Code Listing A.60 demonstrates the use of flock(). (Note that
this code relies on fork() and open(), which are explained in Chapter 2. Advisory locks are
not a critical topic for the main chapter and are provided here for reference after that chapter has
been completed.)
The LOCK_EX | LOCK_NB argument specifies that this process is requesting exclusive (LOCK_EX)
access to the file (only one access at a time) and flock() should run in non-blocking mode
(LOCK_NB). The default behavior of flock() is to cause current process to wait (block) if
another process already has exclusive access. In non-blocking mode, flock() returns a non-zero
value to indicate that the current process failed to acquire the lock. The process can then proceed
to other work that may be necessary and try to acquire the lock at a later time. The call to
sleep() on line 21 is included in this example to create a slight pause in both processes. That
is, without this sleep(), it is possible that one process would run, acquire the lock, and exit
(releasing the lock) before the other process had a chance to try for access. Including line 21
makes such timing unlikely, increasing the likelihood that the reader can observe the effects of the
failed lock when running this code.
In the preceding discussion, we mentioned that advisory locks allow cooperating processes to
coordinate their work. To be precise, two processes are cooperating in this sense only if they
originate from the same original process. That is, the process specifically uses fork() to
create at least one child process. Running the same program multiple times does not create
cooperating processes; these processes would not recognize each other’s claims to locking the file.

Bug Warning
Although it is generally cross-platform, flock() does not successfully create advisory locks on
macOS. For code that truly needs to be cross-platform, fcntl() is the required interface for
advisory locks. The primary disadvantage of fcntl() is that it is an older, generic interface
for many different operations on files. Advisory locks are just one of the possible operations.
C library functions – <fcntl.h>
int fcntl(int fildes, int cmd, ...);- Perform an operation on a file descriptor.
Code Listing A.61 demonstrates the fcntl() interface for creating an advisory lock.
On lines 19 and 26, the F_SETLK argument tells fcntl() that the process is trying to set or
release a lock; the struct reference passed as the third argument distinguishes between these
two actions. Specifically, setting the struct’s l_type field to F_WRLCK indicates the
process is requesting a lock for writing to the file; locking the file for reading would require
also setting the F_RDLCK bit in this field. Setting the l_type field to F_UNLCK and
calling fcntl() again releases the lock on the file.
| [1] | In the UNIX tradition, username refers to the human-readable identifier that user can remember and use easily. Internally, all usernames are mapped to a user ID, which is just an integer value. |
| [2] | These functions are poorly named. The standard definition of the word “truncate” means to
reduce the size of something. However, the C truncate() function can also be used to increase the file’s size. |
| [3] | Typical storage devices organize the device into what is essentially a gigantic array of fixed-size blocks. While the details are more complicated than this, it is sufficient for our purposes to think of accessing a block just as we would index an array. |