2.1. Processes and OS Basics¶

“Don’t wonder if some mishap may happen, but rather ask what one will do about it when it does occur.”
The abstractions of processes, operating systems, and files date back to the earliest computer systems. J. Presper Eckert and John Mauchly used the file abstraction to describe stored programs in the UNIVAC (1951); earlier references in the 1940s also used this concept. Processes were key to the earliest multiprogramming operating systems, such as the Atlas Supervisor (1962) and CTSS (1961). This chapter examines the fundamental building blocks of concurrent systems.
Chapter Objectives
In this chapter, we will address the following instructional objectives:
- We will consider how the kernel resides and operates within the context of a process.
- We will explore how the kernel uses multiprogramming to interleave the execution of multiple processes.
- We will compare and contrast the system call interface with function calls.
- We will examine code relating to the life cycle of a process, including how custom signal handlers can respond to events.
When discussing programming languages like C, Java, or assembly language, we typically talk about writing software programs. Recall that a program is an implementation of an algorithm within a particular programming language. For instance, the function in Code Listing 2.1 is part of a program that documents its algorithm in the comments.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | /* Code Listing 2.1:
A C-based implementation of a recursive factorial calculation algorithm
*/
/* factorial (n) : calculates n!
if n = 1, then factorial (n) = 1
otherwise, factorial (n) = n * factorial (n - 1)
*/
int64_t
factorial (int64_t n)
{
if (n <= 1)
return 1;
else
return n * factorial (n - 1);
}
|
A process is defined to be an instance of a program in execution. What this means is that a process is an active entity that is running through the instructions that are specified in the program. Whenever you run the software program that you have written and compiled into an executable file, you create a new process. Furthermore, if you run the same program several times on the same machine, you typically have multiple processes that are all executing the same code. (We will find that this is not always the case when we discuss threads.)
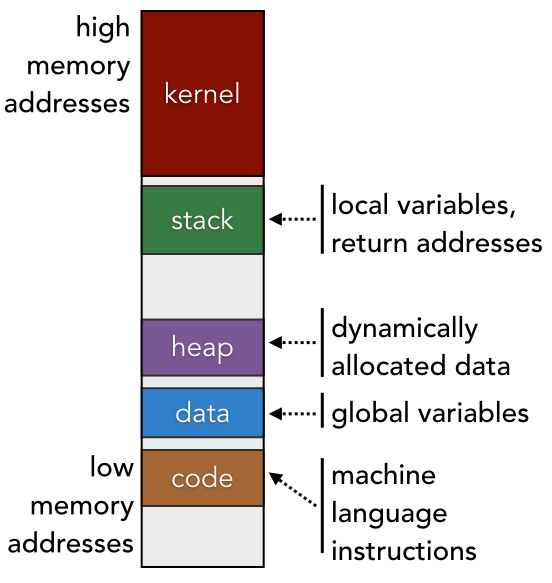
Figure 2.1.3: The major segments stored in a virtual memory instance
A process corresponds to a single instance of virtual memory as shown in Figure 2.1.3. When you run a program, the process is assigned a new virtual memory instance that includes the code, data, heap, and stack segments to contain run-time information. The process executes the instructions as if it were the only piece of software that existed on that hardware. The fundamental goal of working with processes is to establish isolation of programs. If an error occurs in one process (for instance, if your program triggers a segmentation fault), only that process would be affected; the data in other processes would not be harmed, as they would exist in other instances of virtual memory.
The operating system [1] (OS) or kernel is a special program that exists simultaneously within every process. Just like any normal program, the kernel has code, data, heap, and stack segments in memory. Specifically, there is a portion of each process’s virtual memory that is reserved for use by the kernel. [2] This portion of memory can only be accessed when the CPU is set to be in kernel mode. Normal programs run in user mode, which restricts the type of code that can be run and prevents the program from directly accessing shared resources, such as I/O devices.
Although the kernel has many features that are common to normal software programs, it operates in a fundamentally different manner. Specifically, the kernel is designed to be reactive in nature. While normal programs are loaded to perform a certain task from start to finish, the kernel exists in the context of other programs and only executes when it is needed. We say that the kernel is invoked when the normal program requests access to a shared resource or some sort of exceptional condition occurs. When the kernel is invoked, it begins executing within the context of the current process. That is, the kernel behaves as if it is a part of the program that is running. However, the instructions being executed are fetched from the kernel’s code segment. Once the kernel has performed whatever action is was needed for, it hands control back to the user-mode program.
Understanding the relationship between user-mode programs and the kernel is critical to grasping how modern computer systems execute code. In this chapter, we will discuss what the kernel is and how it exists within the context of a process. We’ll also consider how user-mode code interacts with the kernel to take advantage of peripheral hardware components, such as the keyboard or hard drive. Finally, we’ll look at how processes are created and how they receive information about key events through the use of signals.
| [1] | The term operating system is often used in common usage to refer to the collection of programs that provide the basic system environment of a computer. For instance, it is common to hear people talk about the desktop environments provided by the Windows or macOS operating systems. In the context of computer science, however, the term is normally reserved to describe the kernel. The reason for this is that most of the standard services that users and system administrators interact with run at a lower privilege level than the kernel, meaning they are restricted just like normal programs. Throughout this text, we adhere to this convention, that the term operating system is a synonym for the kernel. |
| [2] | In late 2017, security researchers discovered a new form of attack that allowed user-mode code to bypass these protections and access the kernel. To mitigate these attacks, known as Meltdown [Lipp et al., 2018] and Spectre [Kocher et al., 2018], kernel vendors created patches that moved most of the kernel to a separate process. However, the separation is not complete and part of the kernel must remain present in all processes. We omit these details for simplicity and retain the conventional model in which the kernel is co-resident in all processes. |