1.7. Extended Example: Text Parser State Machine¶
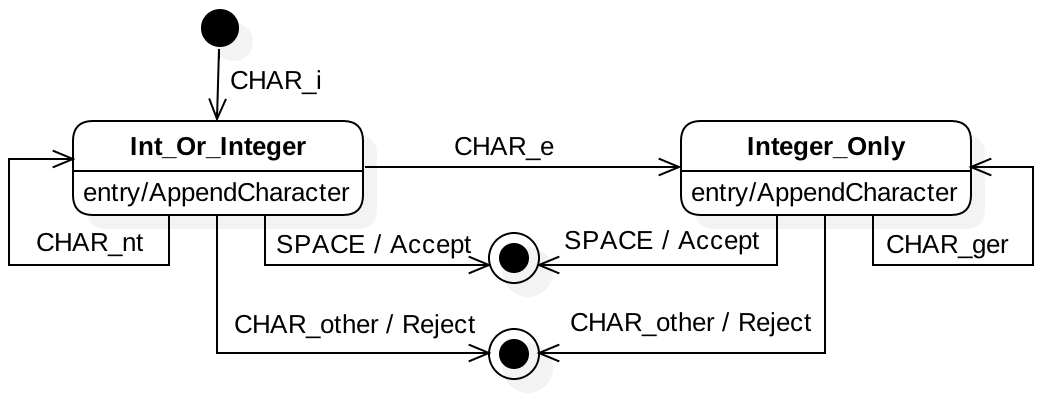
Figure 1.7.1: A UML state model for a simple parser
In this Extended Example, we will illustrate how to use a state machine as a parser. This is a very
simplified version of how compilers read in and parse source code. Figure 1.7.1
shows the state model that we will be using to implement the parser. This parser recognizes only the
strings "int" and "integer", rejecting everything else. Both strings are expected to end
with a space, leading to the Accept final state.
To reduce the size of the model, the character-recognition events (CHAR_*) are fired when the
corresponding character is read from the input in the correct order. For instance, parsing the
string "int" would fire three events in sequence: CHAR_i, CHAR_nt, then CHAR_nt. On
the other hand, parsing string "itn" would fire the events in sequence: CHAR_i then
CHAR_other, because the 't' would not be in the correct order. A more complete model would
use distinct events for each character, as well as separate states to represent the full ordering;
that is, 'i' would lead to a one state, then 'n' would lead to a second, and 't' would
to a third. However, such a model is more difficult to include in the space constraints of the page
here.
First, we complete the generic FSM handler, which we described in Code Listing 1.1 and 1.2. The key
difference here is that there are some additional fields added to the fsm_t declaration. As each
character of the input is processed, it is added to a buffer that keeps track of the string in
progress. Also, to assist the controller in determining which events are valid due to the ordering
of the characters, there are next_valid and next_event fields. For instance, when the FSM
first enters the Int_Or_Integer state, only the character 'i' has been processed.
Consequently the next_valid character would be 'n' and the next_event would be
CHAR_nt. However, once the 'n' is read, the next_valid would change to 't'
accordingly. The final field is used by the controlling driver program to determine if the
string was read completely.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 | #ifndef __statemodel_h__
#define __statemodel_h__
#include <stdbool.h>
#include <sys/types.h>
/* States and events should just be integers */
typedef int state_t;
typedef int event_t;
/* Dummy struct for circular typedefs */
struct fsm;
/* Function pointer type declaration for effects */
typedef void (*action_t) (struct fsm *);
#define BUFFER_LENGTH 10
/* Generic FSM struct that could have other fields, as well */
typedef struct fsm {
state_t state; /* current state */
size_t nevents; /* number of events for this FSM */
/* pointer to the FSM's transition function */
state_t (*transition) (struct fsm *, event_t, action_t *, action_t *);
/* helper fields to keep track of the current input and the
string built so far */
char input;
char buffer[BUFFER_LENGTH];
size_t length;
bool final; /* set on accept or reject */
/* special handling: since there are self-transitions that are
valid a limited number of times, use these fields to keep
track of the next event to fire based on expected input */
char next_valid;
event_t next_event;
} fsm_t;
/* Invoke an event handler for a given FSM */
void handle_event (fsm_t *fsm, event_t event);
#endif
|
Next, we extend Code Listing 1.2 so that it can also perform entry activities on state changes.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | #include <stdio.h>
#include <stdlib.h>
#include "statemodel.h"
void
handle_event (fsm_t *fsm, event_t event)
{
/* Confirm the event is valid for the given FSM */
if (event >= fsm->nevents)
return;
/* Use the FSM's lookup tables; if next is -1, the event is not
Defined for the current state */
action_t effect = NULL;
action_t entry = NULL;
state_t next = fsm->transition (fsm, event, &effect, &entry);
if (next == -1)
return;
/* Perform the effect (if defined) */
if (effect != NULL)
effect (fsm);
/* Perform the new state's entry action (if defined) */
if (entry != NULL)
entry (fsm);
/* Change the state */
fsm->state = next;
}
|
The "parse.h" header file defines the interface to this specific FSM. To control the parser FSM,
a driver program would need access to the event names (defined by the parse_event_t type) and
the name of the initialization function.
1 2 3 4 5 6 7 8 9 10 11 12 13 | #ifndef __parse_h__
#define __parse_h__
#include "statemodel.h"
/* Valid events for this type of FSM */
typedef enum {
CHAR_i, CHAR_nt, CHAR_e, CHAR_ger, CHAR_other, SPACE, NIL
} parse_event_t;
fsm_t *parse_init (void);
#endif
|
The next piece of code extends Code Listing 1.3 with the information needed for the parser
structure. As before, there’s an initialization function (parse_init()) that sets up the
internals of the fsm_t. The append_character() function keeps track of how many times each
particular state has been visited and what character is expected next. Again, a more verbose FSM
would not need this information. Finally, the accept() and reject() functions implement the
transition effects.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 | #include <assert.h>
#include <stdbool.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include "statemodel.h"
#include "parser.h"
/* Internal type definition of states */
typedef enum { ENTER, IOI, IO, ACCEPT, FAIL, NST } parse_t;
#define NUM_STATES (NST+1)
#define NUM_EVENTS (NIL+1)
/* Prototypes for actions/effects and transition function */
static void append_character (fsm_t *);
static void accept (fsm_t *);
static void reject (fsm_t *);
static state_t parse_transition (fsm_t *, event_t, action_t *, action_t *);
/* Return an FSM that links to these internals */
fsm_t *
parse_init (void)
{
fsm_t *fsm = calloc (1, sizeof (fsm_t));
fsm->nevents = NUM_EVENTS;
fsm->state = ENTER;
fsm->transition = parse_transition;
/* Set up internal fields for keeping track of characters */
fsm->input = 0;
memset (fsm->buffer, 0, sizeof (fsm->buffer));
fsm->length = 0;
fsm->next_valid = 'i';
fsm->next_event = CHAR_i;
fsm->final = false;
return fsm;
}
/* Lookup table for transitions; row=state, column=event */
static parse_t const _transition[NUM_STATES][NUM_EVENTS] = {
// C_i C_nt C_e C_ger C_oth SPACE
{ IOI, NST, NST, NST, FAIL, NST }, // Enter
{ NST, IOI, IO, NST, FAIL, ACCEPT }, // Int_Or_Integer
{ NST, NST, NST, IO, FAIL, ACCEPT }, // Integer_Only
{ NST, NST, NST, NST, NST, NST }, // Accept
{ NST, NST, NST, NST, NST, NST }, // Fail
};
/* Lookup table for effects; row=state, column=event */
static action_t const _effect[NUM_STATES][NUM_EVENTS] = {
// C_i C_nt C_e C_ger C_oth SPACE
{ NULL, NULL, NULL, NULL, reject, NULL }, // Enter
{ NULL, NULL, NULL, NULL, reject, accept }, // Int_Or_Integer
{ NULL, NULL, NULL, NULL, reject, accept }, // Integer_Only
{ NULL, NULL, NULL, NULL, NULL, NULL }, // Accept
{ NULL, NULL, NULL, NULL, NULL, NULL }, // Fail
};
/* Lookup table for state entry actions */
static action_t const _entry[NUM_STATES] = {
NULL, append_character, append_character, NULL, NULL
};
/* Given FSM instance and event, perform the table lookups */
static state_t
parse_transition (fsm_t *fsm, event_t event, action_t *effect, action_t *entry)
{
/* If the state/event combination is bad, return -1 */
if (fsm->state >= NST || event >= NIL || _transition[fsm->state][event] == NST)
return -1;
/* Look up the effect and transitions in the tables */
*effect = _effect[fsm->state][event];
/* Look up the next state in the list of entry events */
state_t next = _transition[fsm->state][event];
if (next != NST)
*entry = _entry[next];
return next;
}
/* Appends the current character to the buffer */
static void
append_character (fsm_t *fsm)
{
assert (fsm->length < BUFFER_LENGTH - 1);
fsm->buffer[fsm->length++] = fsm->input;
/* Helper inputs to keep track of what the next event will be */
switch (fsm->input)
{
case 'i':
fsm->next_valid = 'n';
fsm->next_event = CHAR_nt;
break;
case 'n':
fsm->next_valid = 't';
fsm->next_event = CHAR_nt;
break;
case 't':
fsm->next_valid = 'e';
fsm->next_event = CHAR_e;
break;
case 'e':
if (! strcmp (fsm->buffer, "inte"))
fsm->next_valid = 'g';
else
fsm->next_valid = 'r';
fsm->next_event = CHAR_ger;
break;
case 'g':
fsm->next_valid = 'e';
fsm->next_event = CHAR_ger;
break;
default:
fsm->next_valid = '\0';
fsm->next_event = NIL;
}
}
/* Prints that the string is accepted */
static void
accept (fsm_t *fsm)
{
printf ("ACCEPT: \"%s\"\n", fsm->buffer);
fsm->final = true;
}
/* Prints that the string is rejected and at what character */
static void
reject (fsm_t *fsm)
{
printf ("REJECT: \"%s\" at character '%c'\n", fsm->buffer, fsm->input);
fsm->final = true;
}
|
The final piece of code for this parser is the main driver program. This program reads in the
command-line arguments and attempts to parse each one as beginning with either "int" or
"integer". For each provided input, this controller will use parse_init() to create a new
FSM instance. The code in lines 37 – 48 start by checking for a space (indicating the first token
of the input has been read) or for the expected next character (based on the information stored in
the FSM). Based on these checks, line 52 fires the event and the pointer moves on to the next
character. If all characters have been read, there are three possibilities: 1) a space was found and
the match was a success 2) the match already failed, or 3) the input has matched a prefix of
"int" or "integer", but there was no space to terminate the string. To resolve case 3, we
just need to check the strings. [1]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 | #include <stdio.h>
#include <string.h>
#include "statemodel.h"
#include "parser.h"
int
main (int argc, char *argv[])
{
/* Inputs to parse. Matches will be exactly "int", "integer",
or begin with "int " or "integer ". */
if (argc < 2)
{
fprintf (stderr, "Must pass at least one string argument\n");
fprintf (stderr, "Sample command line:\n");
fprintf (stderr, " ./ext int char \"i n t\" integ\n");
return 1;
}
for (int i = 1; i < argc; i++)
{
printf ("Processing input: \"%s\"\n", argv[i]);
/* Create a new parser instance for each input */
fsm_t *fsm = parse_init ();
char *walker = argv[i];
event_t evt = NIL;
/* Traverse through each character in the input */
while (*walker != '\0')
{
fsm->input = *walker;
/* If the input is a space, check if the string
match is successful. Otherwise, check if the
next character matches what is expected. */
if (fsm->input == ' ')
{
if (! strcmp (fsm->buffer, "int") || ! strcmp (fsm->buffer, "integer"))
evt = SPACE;
else
evt = CHAR_other;
}
else if (fsm->input == fsm->next_valid)
evt = fsm->next_event;
else
evt = CHAR_other;
/* The event should never be NIL because of the
logic above, but this style is for consistency. */
if (evt != NIL)
handle_event (fsm, evt);
/* If a string is accepted or rejected, we are done. */
if (fsm->final)
break;
/* Move to the next input character. */
walker++;
}
/* At the end of the input. Either we have matched exactly
"int" or "integer", or we have matched a substring (such
as "inte"). Substrings should be rejected. Use '$' to
indicate an END-OF-STRING character. */
if (!fsm->final)
{
fsm->input = '$';
if (! strcmp (fsm->buffer, "int") || ! strcmp (fsm->buffer, "integer"))
handle_event (fsm, SPACE);
else
handle_event (fsm, CHAR_other);
}
printf ("\n");
}
return 0;
}
|
| [1] | One may object at this point and ask why we didn’t just compare the strings from the
beginning and avoid all of the FSM complexity. The answer is that this example is one miniscule
component of a much larger system: a compiler. The state models used for compilers are
significantly larger and distinguish keywords (such as "int") from programmer-defined variable
names (such as "interest_rate"). Simple string comparison is not a feasible approach to such
complex work. |