4.3. Network Applications and Protocols¶
While the protocol stack adheres to a layered architecture, network applications typically adhere to the client/server or peer-to-peer architectures. In both cases, one or more processes on a host creates a server socket that listens for incoming connections; at a later time, a process on a different host creates a socket to connect to the server socket. In traditional client/server architectures, this client process is contacting the server to request access to a resource, such as a web page or a user’s email messages; clients are typically untrusted and less privileged than servers, requiring some form of authentication to gain access. In a peer-to-peer application, such as file sharing or multimedia streaming, both processes are equally privileged and exchange data in both directions; however, at some previous point, one of the two processes established a server socket that the other connected to.
In many ways, network applications using the socket interface behave like the message passing IPC techniques from the previous chapter. Socket communication can be structured like message queues, or they can use byte streams like pipes or FIFOs. In fact, UNIX domain sockets can be used specifically for this local communication. In addition, a Linux netlink socket provides a mechanism to pass messages between the kernel and a user-mode process. However, if a process needs to communicate with a process on a different host, however, then sockets are required; other forms of IPC do not provide this support.
4.3.1. Naming and Addressing¶
Unlike local IPC, sockets require extra information to set them up. Specifically, when setting up a socket to connect to a remote host, a process must provide information about which host and process to contact. This information is normally provided to the client process by the user in the form of a uniform resource identifier (URI). URIs adhere to a common structure:
URI = scheme:[//authority]path[?query][#fragment]
The scheme component defines the application-layer protocol that is being used; common
examples of schemes would be using http or https for web pages, ftp for file transfers, or ssh to
connect to a remote terminal on another host. The path component consists of a sequence of
data fields, typically organized to create a hierarchy of resources, joined together by a delimiter.
For example, the path in a web page URI defines the location of the requested file in that host’s
file system, relative to the web server’s home directory; if a web server is configured to use the
directory /etc/apache as its home directory, then the path images/icon.gif would be used to
request a copy of the file /etc/apache/images/icon.gif. Note that some applications use a different
delimiter for a path, such as a colon (':').
The bracket notation in the URI indicates that the other components are optional, though some
application protocols may require them. If these components are present, they begin with a
particular identifying character sequence. The query and fragment components begin
with the '?' and '#' characters, respectively, and they can be used to customize the data
requested. For instance, in a web page that is dynamically constructed by the server, the query
might be used to provide user input. One example of this would be an e-commerce application that
uses a URI such as http://mystore.com/itemLookup?itemID=53 to direct the request to a single
server-side file (itemLookup) that performs a database query for item 53, showing its picture,
price, and other information.
The fragment component, on the other hand, is typically used to direct the client application to
customize the view in some way. For instance, a web browser using the fragment field may jump to a
section identified in the HTML source with an anchor tag or an ID attribute, rather than displaying
the default top of the page. The authority component begins with a double slash ('//')
and adheres to the following structure:
authority = [userinfo@]host[:port]
The host field is either a domain name or an IP address that is used to locate the host within
the network. The port number is used to identify the process that should receive the application
data from the packet. Many protocols have a default port number, such as using port 80 for a web
server communicating via HTTP. Application clients, such as web browsers, fill in this information
automatically. For instance, entering http://www.foo.com/ and http://www.foo.com:80/ would
yield the same results; both URIs contain the same scheme (http), the same host
(www.foo.com), the same path ('/'), and the same port (80, implied in the former). The
userinfo field is used if a user identity needs to be associated with the request, as when using
SSH to log into a user’s account.
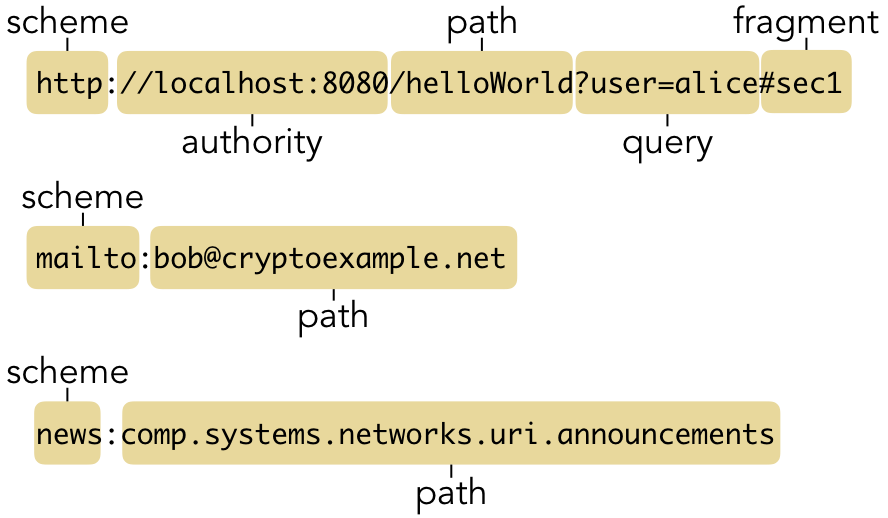
Figure 4.3.1: The structure of URIs for three applications
Figure 4.3.1 illustrates the structure of URIs for three example applications. The
first URI shown illustrates one that may be used to access a page from a web server running on the
user’s own machine (as indicated by the localhost host name in the authority field). Port 8080
is commonly used as the default port number for local instances of the Apache Tomcat server; so this
URI may be used to access a Java servlet, providing the username as an input value, then jumping
down to the section identified by the sec1 HTML ID attribute. The second example shows a URI as it
may be used in an email application. Note that the URI definition does not impose strict
requirements on the structure of a path, so an email address is acceptable for that application. The
last example shows a URI for accessing a newsgroup.
4.3.2. Protocol Specifications and RFCs¶
The protocols that govern communication in the Internet are defined and maintained by the Internet Engineering Task Force (IETF), an international standards organization; IETF is a part of a larger non-profit organization, the Internet Society (ISOC), that is responsible for the leadership and development of the Internet. The aim of IETF is to publish standards to make the Internet work better, relying on an open and transparent process with a significant amount of volunteer and community effort. The IETF defines these standards in documents known as requests for comment (RFCs). [1] All RFCs are available for free download at https://tools.ietf.org/rfc/.
Table 4.1 identifies the RFC for several well-known protocols and components of the Internet. To be thorough, as shown in the table, there is even a specific RFC that defines the process for creating an RFC. Many protocols, such as TCP and IP, have a single core RFC but depend on several others beyond the main document. Other protocols spread their core definition over several RFCs; for example, the secure shell protocol (SSH) is defined in RFCs 4250 – 4254, with several other RFCs defining supporting components. Note that there are many protocols and services, such as the secure copy protocol (SCP), that are not defined in any RFC.
| RFC | Purpose |
|---|---|
| 768 | UDP – unreliable transport layer protocol |
| 791 | IPv4 – network layer protocol (version 4) |
| 793 | TCP – reliable transport layer protocol |
| 959 | FTP – file transfer protocol |
| 1034,1035 | DNS – domain name translation database |
| 2026 | Defines the RFC process |
| 2131 | DHCP – dynamic IP addressing |
| 2616 | HTTP/1.1 – serving web page |
| 3986 | Structure and interpretation of a URI |
| 8200 | IPv6 – network layer protocol (version 6) |
Table 4.1: RFCs for some well-known Internet services
RFCs for protocols typically include multiple sections, such as definitions of key terms, illustrations of the structure and timing of messages, explanations status and error messages, and security analyses. Some RFCs are very short, as short as a few pages in PDF format; others can be more than 100 pages. One key feature that is common is the use of :ackus-Naur Form (BNF), a formal method for defining information about a language or a set of messages. Reading BNF is a key skill for understanding the protocol specifications in RFCs. As an example, consider the following portion of the HTTP/1.1 specification in RFC 2616:
HTTP-message = Request | Response
Request = Request-line
*(( general-header
| request-header
| entity-header ) CRLF)
CRLF
[ message-body ]
Request-Line = Method SP Request-URI SP HTTP-Version CRLF
These lines illustrate several key features of BNF. The text to the left of an equal sign ('=')
declare a unique type of entity that serves as a basic language feature; in this case, these
lines define the structure of the entities HTTP-message, Request, and Request-Line. The
vertical bar ('|') denotes a choice operation that can be satisfied by either entity; for
instance, an HTTP-message can be either a Request or a Response. Consecutive lines
indicate multiple entities that are required in a particular sequence; the line breaks in BNF do not
have a specific meaning and only serve the purpose of making the definition more readable. The
parentheses are used for grouping entities, the Kleene star character ('*') indicates
that an entity may appear zero or more times, and the brackets indicate an optional entity that may
appear once or may be omitted. The CRLF entity denotes the character sequence “carriage
return-line feed” that consists of ASCII character 13 ('\r') followed by ASCII character 10
('\n'), and the SP entity denotes a single space (ASCII code 32, ' ').

Example 4.3.1
To combine these BNF rules in an example, an HTTP Request must begin with exactly one
Request-line followed by some sequence of entities (possibly an empty sequence) that must be
either a general-header, request-header, or entity-header; there can be multiple
instances of each of these headers and they can appear in any order. After all of the headers,
there must be a single blank line ending in CRLF, followed by an optional message body. The
Request-line that starts the Request must consist of a Method (such as GET or
POST), a Request-URI (which is different but related to the general URI previously
discussed), and an HTTP-Version, separated by spaces and ending with a CRLF. As an example,
the following lines of code is a valid HTTP-message:
GET index.html HTTP/1.0
Accept-Charset: iso-8859-5, Unicode-1-1
Date: Tue, 19 Nov 2018 08:12:31 GMT
Accept-Encoding: *
This example illustrates a GET request using HTTP version 1.0 to request a copy of the file
designated by the Request-URI index.html. The Accept-Charset and Accept-Encoding
lines are examples of the request-header entity types, while the Date is a
general-header. Each line ends with a CRLF, including the last line, which has no other
text.
| [1] | The term request for comment may seem to suggest that the document is an early draft that will be revised later after feedback from the community. This is, to an extent, actually true. The protocols themselves are frequently revised or extended, so many RFCs obsolete others as the structure and functioning of the Internet evolves. Consequently, the name RFC is appropriate because they serve as requests for the public to consider the current status of the Internet, proposing improvements where needed. |