6.2. Processes vs. Threads¶
Recall from Processes and OS Basics that a process is fundamentally defined by having a unique virtual memory space. The process contains a code segment that consists of the executable machine-language instructions, while the statically allocated global variables are stored in the data segment. The heap and stack segments contain the dynamically allocated data and local variables for this execution of the program.
Every process begins by executing the instructions contained in main(). The
%pc register defines the flow of the code by pointing to the next
instruction to be executed. The call instruction can modify the control flow by
jumping to other functions. When this happens, the return address (and other
related information) is placed on the stack to maintain the program’s logical
flow. This single, logical sequence of executing instructions within a process
is known as a thread of execution, which we typically just call a thread.
6.2.1. Multithreading¶
Multithreaded processes have multiple threads that perform tasks
concurrently. Just like the thread that runs the code in main(), additional
threads each use a function as an entry point. To maintain the logical flow of
these additional threads, each thread is assigned a separate stack. However, all
of the other segments of memory, including the code, global data, heap, and
kernel, are shared.
Another way to consider the relationship between threads and processes is to separate the system functions of scheduling and resource ownership. Switching from one thread to another would change the system from working toward one computational goal to working toward another. This means that the purpose of switching between threads is to create a schedule that controls when each thread is running on the CPU.
On the other hand, processes act as containers for resource ownership. As the process runs, it may request access to files stored on the disk, open network connections, or request the creation of a new window on the desktop. All of these resources are allocated to the process, not individual threads.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | /* Code Listing 6.1:
Structure of a simple multithreaded program framework
*/
#include <stdio.h>
/* Include thread libraries */
int number = 3;
void *
thread_A (void* args)
{
int x = 5;
printf ("A: %d\n", x + number);
/* Exit thread */
}
void *
thread_B (void* args)
{
int y = 2;
printf ("B: %d\n", y + number);
/* Exit thread */
}
int
main (int argc, char** argv)
{
/* Create thread A */
/* Create thread B */
/* Wait for threads to finish */
return 0;
}
|
Code Listing 6.1 shows the structure of a simple program that creates two
threads that run concurrently. For now, comments are used to indicate where the
thread management code would be written. Thread A declares a local variable
x and prints out the message A: 8, which is the sum of the value of x
(5) and the global variable number (3). Thread B declares y and prints
out B: 5, for similar reasons. One observation about this sample is that the
code for the threads looks like normal functions in a typical program. The
difference only becomes apparent when we run the program.
When the program is run, the scheduling that controls when the threads run is nondeterministic from the programmer’s perspective. By looking at the code, we can conclude that line 13 runs before line 14, just like line 21 runs before line 22. However, we cannot predict the ordering between line 13 and line 21. This choice is made at run-time and is controlled by the kernel. When looking at source code for multithreaded programs, we assume the lines of code are interleaved, meaning that the kernel can switch back and forth whenever it chooses to do so.

Example 6.2.1
Table 6.1 shows three of the possible interleavings of Code Listing 6.1. In each of these cases, the indentation is used to indicate which thread performs an action (thread A is not indented and thread B is). In interleaving 1, thread A runs to completion before thread B starts. In interleaving 2, thread B sets the value of y before thread A prints its message. Note that this timing is not observed without a debugger, since setting y produces no visible result. Finally, in interleaving 3, thread B’s print statement occurs before thread A’s.
| Interleaving 1 | Interleaving 2 | Interleaving 3 |
|---|---|---|
x = 5 |
x = 5 |
y = 2 |
More interleavings are possible than those shown in Table 6.1. The only requirement is that the order of instructions within a single thread must match the order specified in the code. The selection of which thread has an instruction run is seemingly randomized.
6.2.2. Advantages and Disadvantages of Threads¶
Using multiple threads offers a number of advantages over creating an application from multiple processes. First, using multiple threads helps programmers build modularity into their code more effectively. Complex software, especially the types of applications built with object-oriented programming, typically involves modular components that interact with each other. Oftentimes, the program can run more efficiently if these components can run concurrently without performing context switches. Threads provide a foundation for this programming goal.
One common example of using threads for different purposes is an interactive graphical user interface. Application programmers build in keyboard or mouse listeners that are responsible for detecting and responding to key presses, mouse clicks, and other such events. These types of event listeners are simply concurrent threads within the process. By implementing the listener behavior in a separate thread, the programmer can simplify the structure of the program.
Threads also require significantly less overhead for switching and for communicating. A process context switch requires changing the system’s current view of virtual memory, which is a time-consuming operation. Switching from one thread to another is a lot faster. For two processes to exchange data, they have to initiate interprocess communication (IPC), which requires asking the kernel for help. IPC generally involves performing at least one context switch. Since all threads in a process share the heap, data, and code, there is no need to get the kernel involved. The threads can communicate directly by reading and writing global variables.
At the same time, the lack of isolation between threads in a single process can also lead to some disadvantages. If one thread crashes due to a segmentation fault or other error, all other threads and the entire process are killed. This situation can lead to data and system corruption if the other threads were in the middle of some important task.
As an example, assume that the application is a server program with one thread responsible for logging all requests and a separate thread for handling the requests. If the request handler thread crashes before the logging thread has a chance to write the request to its log file, there would be no record of the request. The system administrators left to determine what went wrong would have no information about the request, so they may waste a lot of time validating other requests that were all good.
The lack of isolation between threads also creates a new type of programming bugs called race conditions. In a race condition, the behavior of the program depends on the timing of the thread scheduling. One example of a race condition is when two threads both try to change the value of a global variable. The final value of the global variable would depend on which thread set the value last.
6.2.3. Thread Models¶
Throughout this chapter, we will be focusing on the POSIX thread model, which is
independent of language and OS (though mostly associated with UNIX-like OS). The
POSIX specification defines a thread as a single flow of control within a
process. Based on this definition, all threads within a process exist in a
single address space; as such, all threads in a process can access anything
stored in memory if the address can be determined. On the other hand, each
thread has a unique copy of certain pieces of data that are required for
execution; these unique copies include the errno variable (used for
detecting errors that occur in C standard library functions), general purpose
registers, and a stack pointer. Table 6.2 summarizes what the POSIX
specificat declares is unique per thread and what is accessible to all threads.
| Unique per thread | Accessible by all threads in process |
|---|---|
|
|
In typical implementations, scheduling of POSIX threads is typically performed by the kernel. This approach allows the kernel to make scheduling decisions consistently across processes, while also making context switches between threads efficient (as the virtual memory image does not change). The POSIX model is not the only way to structure and organize threads. There are other models that have been used for multithreading in a variety of systems.
Early versions of Java used the Green threads model (named for the Green Team inside the Sun Microsystems that implemented the library). In this model, the Java virtual machine (JVM), which ran as a single process, is responsible for scheduling between threads in an application. The kernel underlying the JVM had no awareness of the presence of multiple threads. An advantage of this approach is that switching between threads is efficient, as there are no system calls that require the intervention of the kernel. However, all threads had to subdivide the process’s given CPU time; as the number of threads increased, performance would dramatically decrease, as each thread would get less and less CPU time.
Solaris and other forms of System V UNIX adopted a model known as light-weight processes (LWPs). In this model, multiple LWPs within a single process execute on top of a single kernel thread. Like the Green threads model, scheduling between LWPs is handled by a user-mode thread library rather than the kernel. However, unlike Green threads, the LWP model allows a single process to run on top of multiple kernel threads. This approach creates a many-to-many relationship between user- and kernel-mode threads. Consequently, processes with several LWPs could distribute their execution time across multiple kernel threads for more CPU time.
Windows and the .NET framework use a fiber model, which is similar to the POSIX model. Like a POSIX thread, fibers share a single address space and each fiber is mapped to a single kernel thread. The primary difference is that fibers within a single process use cooperative multitasking. This approach offers a significant advantage for ensuring safe access to resources shared between the threads, as the fibers have greater control over when switches occur.
Figure 6.2.2 summarizes how the four threading models map user threads to kernel threads. In all cases but Green threads, we assume that the process consists of three kernel threads that can be scheduled independently. The POSIX threads and fibers form a 1:1 model from user threads to kernel threads, with the primary difference being the intervention of the fiber scheduler. The Green threads model forms an N:1 relationship, as the kernel is not aware of the multiple threads running on top of the JVM. The LWP model is described as M:N because there is no direct link between the number of user and kernel threads. For each of the N kernel threads, there is a virtual CPU, and the LWP library dynamically maps the M user threads to these virtual CPUs according to its own scheduling policies.
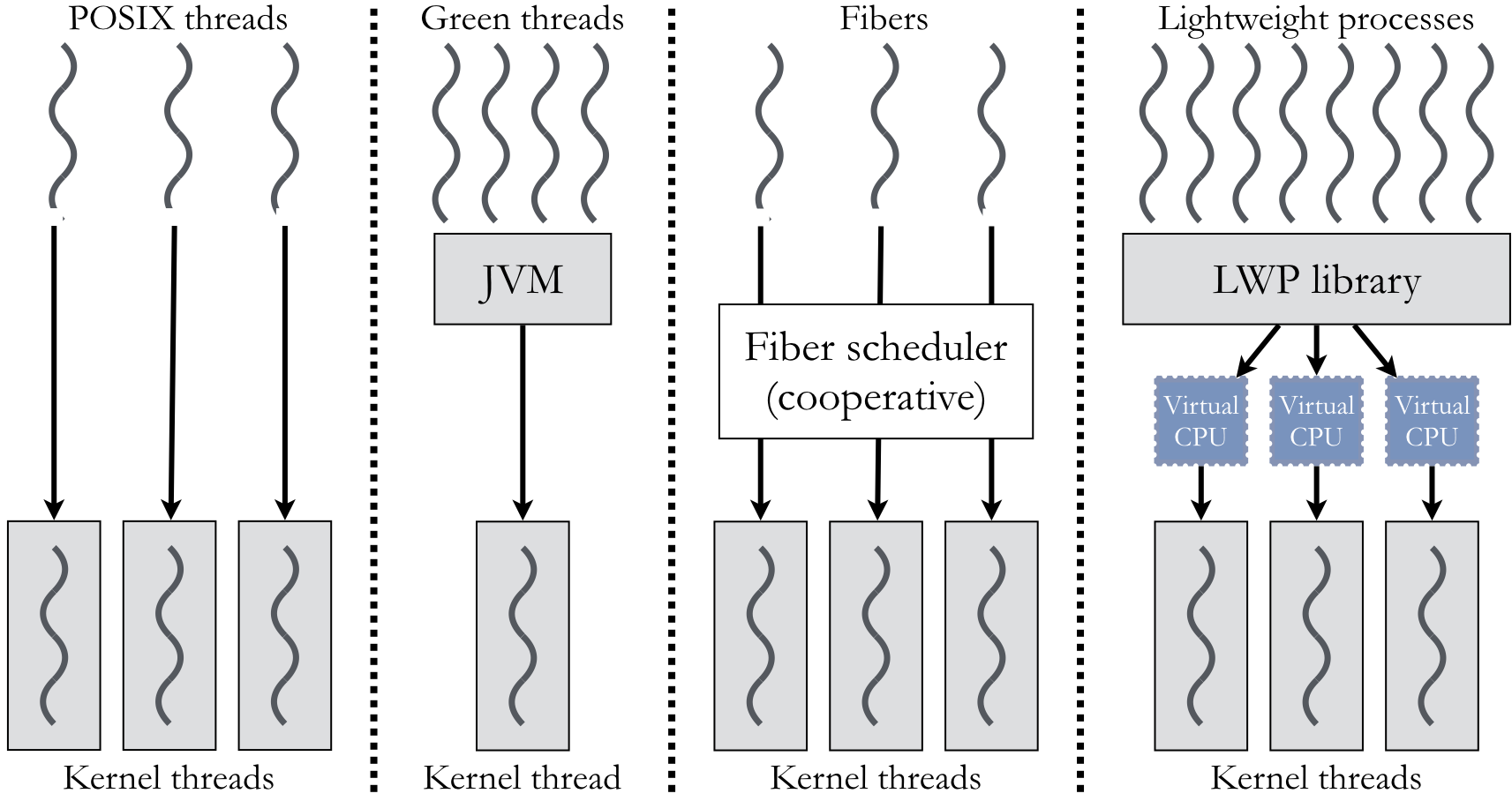
Figure 6.2.2: Mapping models for POSIX, Green threads, fibers, and lightweight processes