4.2. The TCP/IP Internet Model¶
Modern computing systems rely on the Internet for communication. The Internet is not a single computer network. Rather, the Internet is a network of interconnected networks that communicate using a common set of protocols, specifications that define the structure and other requirements for messages between computers. The messages originate with hosts—computers and similar connected devices—at the network edge. The messages are then passed (or forwarded) between routers, devices that are connected in a way that creates the structure of the network. The network core that serves as the basis of the Internet is the backbone, which refers to the connected networks that are controlled and maintained by a few telecommunications companies, such as AT&T and CenturyLink. These backbone providers sell access to Tier 1 Internet Service Providers (ISPs), including Level 3, Cogent, and GTT. Note that there is some overlap in these companies, as backbone providers can also be Tier 1 ISPs; these companies sell access to the communication lines to each other based on peering agreements.
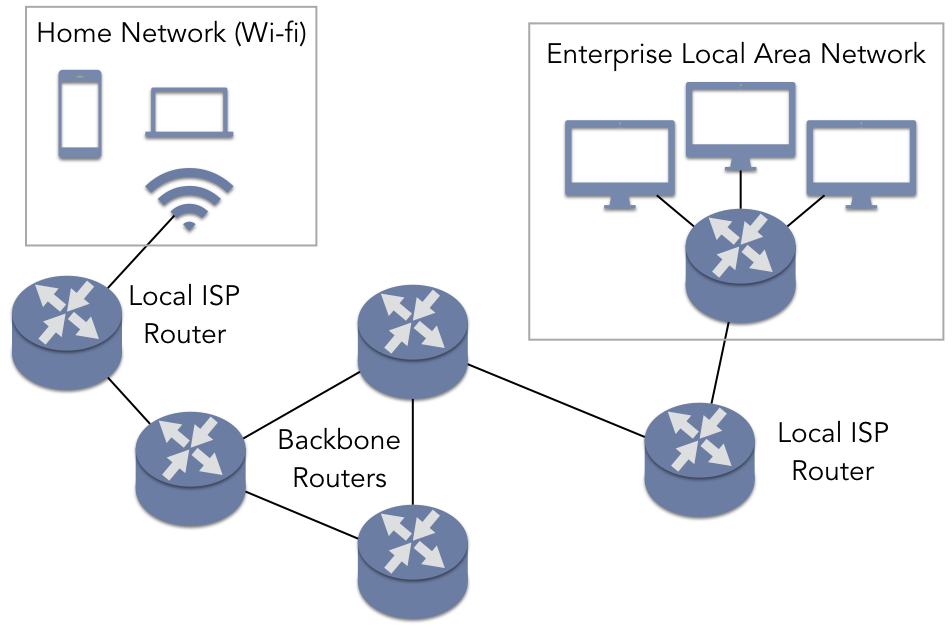
Figure 4.2.1: Home and enterprise networks connect through local ISPs and the Internet backbone
Figure 4.2.1 illustrates the basic structure of how computer systems connect through the Internet. A family may create a home network by setting up a Wi-Fi router that serves as an access point for laptops, smartphones, gaming systems, smart TVs, or other such consumer devices. This Wi-Fi router is connected to a local ISP using a subscription service, such as cable modem access. The local ISP has an internal network that connects to other ISPs, eventually leading to a Tier 1 ISP. Similarly, companies can set up their own enterprise local area network (LAN), allowing their computers to exchange data directly. Just like the home user, the company running the enterprise LAN would need to have a subscription for service from a local ISP in order for their employees to have Internet access. This company may also be acting as a content provider that creates services such as email, cloud computing data storage, or web sites.
4.2.1. Internet Model¶
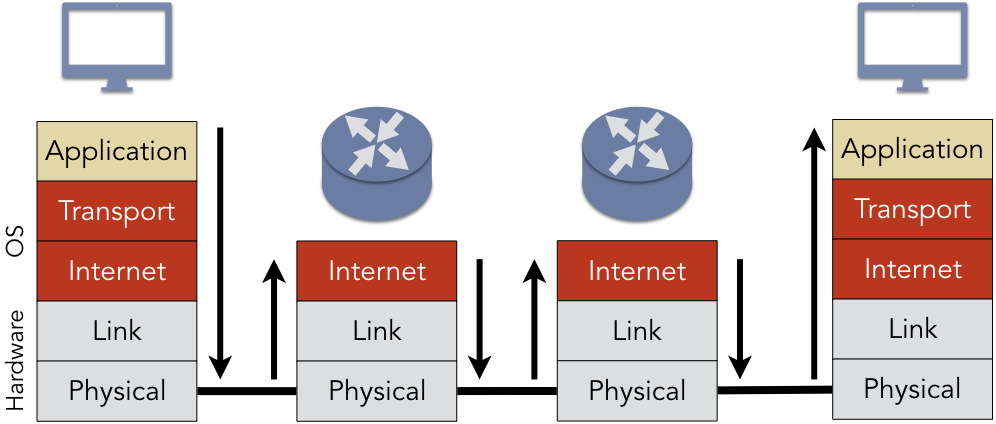
Figure 4.2.2: The five layers of Internet communcation
Network communication adheres to a layered architecture, which is commonly described using the Internet model, as illustrated in Figure 4.2.2. The application layer consists of the logical endpoints of the communication within applications; for instance, a web browser operating at the application layer at one end may establish a connection to a web server running in the application layer at the other endpoint. The applications at the two hosts cannot directly communicate. Instead, the application opens a socket, the software endpoint for the connection. Sockets can be considered a form of message passing IPC that is primarily used for network communication; at either end, the processes write to and read from the socket using system calls.
The sockets provide the process with an interface to the transport layer, which is typically
implemented in the OS. The transport layer provides some key services that make the network
communication more usable to the application layer. The transport layer breaks application layer
messages—which may be large—into fixed-size data segments for delivery. The
transport layer then provides a multiplexing service, allowing all processes on a single
host to share a single network connection. At the receiving end, the transport layer performs
demultiplexing, directing the data to the appropriate process. Multiplexing and
demultiplexing are achieved through the use of a port number, which is an integer associated
with a particular process; at each host, only a single process can be assigned to a particular port
number at a time. Furthermore, packets can arrive at their destination out of order, so part of the
demultiplexing service is to reassemble the application-layer messages in the expected order. For
instance, when accessing a web page, the browser may send the application-layer message starting
with "GET /index.html HTTP/1.1". The demultiplexing service would ensure the data is read by the
web server’s socket in that order, rather than "ex.html HTTP/1.1GET /ind". It is very unlikely
that messages this small would be split across multiple packets, but it is common for larger messages.
As the amount of data sent by applications increases, networks can experience congestion. When this happens, packets can be lost or significantly delayed. To address this problem, some transport layer protocols, such as Transmission Control Protocol (TCP), also provide flow control and reliable transport services. When the network is experiencing a significant amount of congestion, the flow control will slow down the rate that the host sends new packets into the network; with enough hosts doing this, the congestion will gradually drop and the performance will increase. When packets are lost in transit, reliable transport will detect the lost data and send a request for the data to be resent. TCP is also a connection-oriented protocol, which means that the two hosts store persistent state information between messages. In contrast, User Datagram Protocol (UDP) is a connectionless protocol that does not maintain state between messages; each message that arrives at a server is treated as if it is from a new, unique client. UDP is also an unreliable transport protocol, meaning that it does not attempt to correct errors from lost data.
When the transport layer needs to send or receive packets, the transport layer protocol contacts the Internet layer. The Internet layer provides the logical structure of the connections between hosts. That is, while the transport layer provides end-to-end communication for processes on the two hosts, the Internet layer provides point-to-point communication between the hosts and routers, both within and across network boundaries. The Internet Protocol (IP) operates at this layer, associating a logical identifier—known as an IP address—with a host or router connected to the network. Network-layer protocols define the routing path that packets will traverse through the Internet. That is, when a local ISP router receives a packet from a subscriber, the router examines the intended destination IP address and sends the packet to another router based on its best guess for the shortest path to get there.
The lowest layers of this model are the link and physical layers, which are typically designed and implemented together in the hardware devices. The reason for this co-design is that the protocol depends on the underlying physical transmission technique. A desktop or server may be using the Ethernet suite of protocols to send pulses of light over a fiber optic cable. A laptop communicating with a Wi-Fi access point may be using the IEEE 802.11 family of protocols that encode bits on radio waves. A smartphone, on the other hand, may be using a 5G link that uses a different type of radio that requires a different encoding technique.
The link and Internet layers serve a similar purpose, which is to create links between computer systems. The key difference is the layer of abstraction at which they operate. Link layer protocols can only send packets to other devices within the same network, as they are tied closely to the physical connection; for instance, the purpose of Ethernet is to transmit bits between two devices that are physically connected by a cable. The Internet layer protocols operate at a higher level of abstraction, as two consecutive routers may not be physically connected. Rather, one router may be connected to a network switch [1], a specialized device that provides high-speed packet forwarding within a LAN. That switch may be connected to another, which is connected to a third, and so on until the other router is reached. These individual point-to-point connections between switches may involve different link protocols or versions, such as alternating between the 100BASE-T (100 Mbit/s transmission speed) and 10GBASE-T (10 Gbit/s) versions of Ethernet. Thus, what looks like a single connection or hop between routers in the Internet layer may require traversing several point-to-point links between switches in the link layer.

Note
The Internet model that we have described here is mostly based on the official model described in RFC 1122, which specifies requirements for Internet hosts. To be precise, RFC 1122 does not include the physical layer in the model, but we find it is useful to include for completeness. Other books and resources also deviate from RFC 1122 in a variety of ways, such as slightly different naming conventions (network layer instead of Internet layer, data link layer or network access instead of link layer). These details are not generally a major concern, but readers should be aware that these variations in terminology exist.
4.2.2. Packet Encapsulation and Nomenclature¶
As the network data is passed down the protocol stack, each layer’s data needs to be preserved until it is ready to be used by the receiver. This is accomplished by encapsulating each layer’s data as the payload for the next layer, attaching a metadata header that contains information used by the lower layer. For instance, the transport-layer header would indicate if this packet is being sent using TCP or UDP, a protocol that does not provide reliable delivery. The headers also may contain information about the size of the payload or a checksum of its contents; this information can be used to determine if the data has been transmitted correctly or if some or all of it has been lost or corrupted.
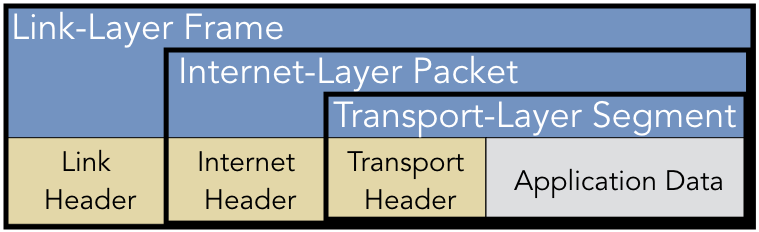
Figure 4.2.4: Data from each layer is encapsulated
A side effect of creating layered architectures like the Internet model is that the final composition often exhibits the frustrating characteristic of redundant nomenclature. As each layer is defined to be independent of the others, it is common for the protocols at each layer to use different terminology for the same idea. Figure 4.2.4 illustrates the layer encapsulation for the Internet model. Application-layer becomes the payload for a transport-layer segment with a header that contains information about the end-to-end delivery between processes. The network-layer packet encapsulates a segment with information needed to route the message between hosts. The link-layer frame adds a header that facilitates the physical transmission of the information within a LAN.
While different layers use different terms for the same concept, there often is a nuanced difference between the two. For instance, a transport-layer segment generally varies considerably in size, containing the full contents of a single application-layer payload. On the other hand, network-layer packets may take a single segment and break it into multiple fragments that are sent independently. Similarly, the term datagram is often used as a synonym for packet. The subtle difference is that packet is generally associated just with the Internet layer, whereas datagram has a looser connotation; datagram can sometimes be used at other layers to refer to the presence of unreliable data transfers. Finally, the terms byte and octet typically refer to a collection of eight bits. The difference here is that some architectures use byte to denote the basic information unit size, which is allowed to vary; thus, a byte is not always guaranteed to be eight bits, whereas an octet must be. Additionally, in some cases, an octet is read right-to-left instead of left-to-right; that is, the decimal value 5 may be denoted by the octet 10100000 instead of 00000101. Oftentimes, these subtle differences in terminology do not have a significant impact on the discussion, but it is important to note they exist.
| [1] | Note the different terminology for similar devices. The term router is used to describe a device that operates at the Internet layer; a switch only operates as high as the link layer and does not provide the higher layers of the protocol stack. |