9.2. Parallelism vs. Concurrency¶
As a starting point, it is important to emphasize that the terms concurrency and parallelism are often used as synonyms, but there is a distinction. Both terms generally refer to the execution of multiple tasks within the same time frame. However, concurrency does not necessarily mean that the tasks are simultaneously running at any given moment. Instead, concurrency can be achieved on a single-core processor through the use of multiprogramming. In multiprogramming, the OS rapidly switches back and forth between multiple programs that have been loaded into memory. We can say that blocks of the two programs’ instructions are interleaved, meaning that the processor alternates which program is running. Because this happens so quickly, the concurrency provided by multiprogramming creates the illusion of parallel execution. The user believes the two programs are running at the same time, but they actually are not. Within a single program, concurrency is focused on the logical structure of the tasks involved. For example, a program with a graphical user interface employs concurrency by creating separate threads for handling keyboard input, auto-saving backup copies of modified files, responding to mouse clicks or screen touches, and so on.
In contrast, parallelism means that the multiple tasks are simultaneously executing. The goal in parallelism is focused more on improving the throughput (the amount of work done in a given amount of time) and latency (the time until completion of a task) of the system. In essence, parallelism is focused on trying to do more work faster. Parallel execution implies that there is concurrency, but not the other way around. As a starting point for parallel programming, we often talk about identifying opportunities for concurrency, then apply techniques to parallelize the concurrent tasks.
9.2.1. Multiprocessing Systems¶
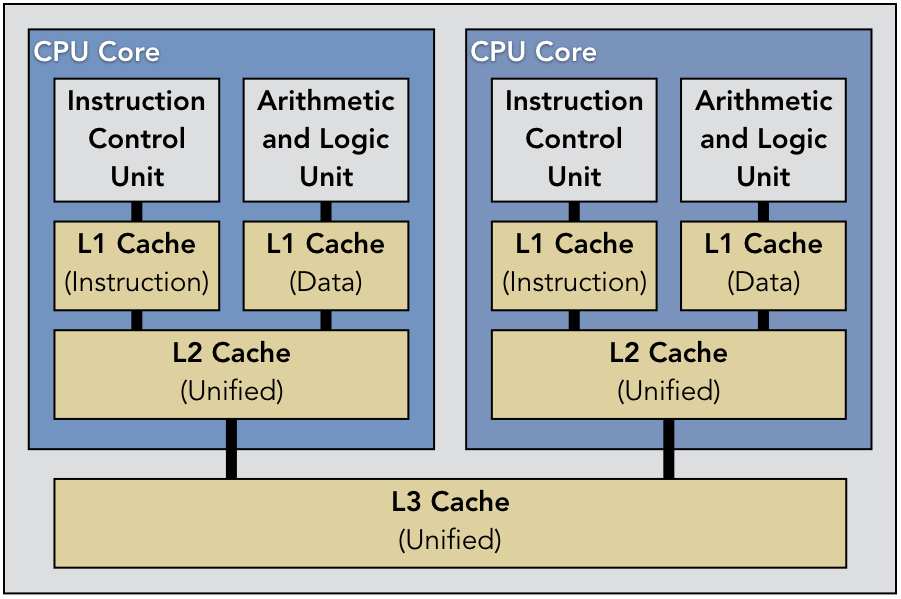
Figure 9.2.1: A typical cache and core arrangement for a dual-core system
Parallelism requires hardware that is capable of multiprocessing, which is the ability to execute multiple processes simultaneously. In the case of a multicore system (which would include a typical modern laptop computer), the CPU has multiple distinct physical processing cores that are all capable of executing instructions. That is, each core acts as a miniature version of a CPU, with its own instruction control unit, ALU, and cache memory. In a multicore system, the OS can arrange to execute the two programs simultaneously on separate cores. Figure 9.2.1 shows the logical structure of a typical dual-core system, with three levels of caching. In this scenario, the L2 and L3 cache levels are unified, storing both data and instructions; the L1 caches are banked, with one cache per core devoted to instructions and another devoted to data.
Another form is symmetric multiprocessing (SMP), which is the class of systems that contain multiple CPUs interconnected within a single machine. As all CPUs in an SMP system share the same memory, the hardware design tends to be complex, making the system expensive to build and maintain. Cluster systems, on the other hand, use multiple machines closely connected on a network. Cluster systems tend to use standard hardware, making it possible to drastically increase the number of processing units relative to a similarly priced SMP system. The tradeoff is that communication between nodes in a cluster is slower than SMP, because the communication takes place over a network rather than through shared memory.
The power of multiprocessing is not restricted to kernel designers. Rather, many types of systems and application software can be built to leverage these platforms for complex and efficient software. While concurrent program can be challenging, there are many common parallel design patterns that provide effective strategies for exploiting parallelism.