0.1. About OpenCSF¶
“Computers are useless. They can only give you answers.”
Why this book is needed
As the field of Computer Science continues to evolve and expand, there is an increasing amount of pressure to increase the size of the discipline at the undergraduate level. While traditional systems areas, such as Computer Organization, Operating Systems, and Computer Networks, remain critical foundations, there are growing calls to include newer topics, such as Parallel Computing and Distributed Systems. In addition, existing systems-related areas such as Computer and Information Security continue to grow in both scope and importance.
To compensate for this increase in systems-related demand, the ACM Computing Curriculum 2013 (CC2013) adopted a flexible two-tier system for defining what constituted the core of the discipline. Under this system, Computer Science departments are advised to cover 100% of the topics identified as Core Tier 1, while also striving for 80% of Core Tier 2 topics. As part of this change, CC2013 introduced the System Fundamentals knowledge area as Core Tier 1 material. This knowledge area was intended to cover common design principles, themes, and concepts that span multiple of the traditional systems areas.
The aim of this book is to provide a breadth-first overview of concurrent systems architectures and programming. Specifically, this book aims to cover 100% of the Core Tier 1 material for the areas of System Fundamentals, Operating Systems, Network-centric Computing, and Parallel and Distributed Computing. In achieving this coverage, this book provides a flexible foundation for undergraduate Computer Science programs to achieve Core Tier 1 coverage while customizing their curriculum for Core Tier 2 as appropriate for their students. Furthermore, this approach provides a foundational scaffold for additional systems courses that can apply these principles and concepts with more in-depth study of specific areas.
Assumed background knowledge and coding style
This book relies on a working knowledge of Computer Organization and C programming. Specifically, this book assumes that readers are familiar with the C memory model, including memory addresses and pointers, as well as the relationship between high-level languages and assembly language. A specific knowledge of x86 assembly language is not necessary, as most references to it rely almost exclusively on instructions that are similar to other assembly languages.
In our C programming examples, our aim is to provide cross-platform support as much as possible. That is, as much as possible, our code samples will work identically on any UNIX (such as macOS) or Linux system. We use the GNU coding style, adhering to the C99 and POSIX.1-2017 standards. The primary exception to this approach is the chapter on Interprocess Communication (IPC), which is inherently platform dependent. For instance, macOS employs System V IPC semantics and only supports a limited subset of POSIX IPC features; on the other hand, POSIX is the preferred interface for Linux. As such, avoiding the interface conflicts is unavoidable. To reduce the impact of this conflict, however, we will focus on the POSIX interface in the main text
Guiding educational philosophy principles
While the focus in this book is obviously on concurrent computing systems, we approach this topic from a pragmatic stance rooted in active learning. Specifically, throughout the text, our emphasis is to focus on the application of systems concepts and integrating this material to the readers’ prior knowledge. Our aim is to provide a solid foundation of core computer systems ideas to all students, regardless of whether they go on to pursue advanced study in the systems area or other domains.
Throughout the book, we strive to illustrate concepts based on the notion of worked examples. Within the context of this book, we apply this idea by providing working code wherever feasible, with comments and the surrounding text documenting the code to identify the key steps that explain why the code works. For some particularly advanced concepts, providing succinct illustrative code for an undergraduate context is simply not feasible. However, we deliberately try to explain concepts with code as much as possible to keep the discussion concrete and practical.
Text conventions
Throughout this text, we use a number of text boxes and structures to highlight key ideas and concepts. As noted previously, this book places a heavy emphasis on providing working code samples. To achieve this goal, we highlight key C functions in boxes structured as below. These boxes start by identifying the required header file (unistd.h in this case) to include. Each function listed includes the function prototype and a brief description.

C library functions – <unistd.h>
pid_t fork(void);
Create a new process.
Code listings provide minimally functional code to illustrate these functions’ uses. Each listing uses line numbers so that the surrounding text can more easily emphasize key lines. Each listing is numbered as N.M, with N being the chapter number and M specifying a numerical order within the chapter. All code listings are available for download at https://csftext.org/. Each chapter ends with an Extended Example that is not explicitly numbered as a code listing. These Extended Examples are complete stand-alone programs that provide a full implementation of how to apply the chapter’s concepts.
1 2 3 4 5 | /* Code Listing N.M:
Sample code to illustrate a point
*/
pid_t child = fork ();
|
We use three types of text boxes to emphasize certain points throughout the text. These boxes use the icons and title structures shown here.

Bug Warning
The text in this box describes common coding errors, some of which can lead to serious security vulnerabilities and system crashes.

Example 0.1.1
These examples provide a concrete instance to illustrate a general concept. These examples often focus on mathematical calculations using formulas recently described or provide a specific example of the binary data that makes up a message header or contents. These examples are numbered (again, with N as the chapter number and M increasing numerically) so that the surrounding text can compare and contrast examples as needed.

Note
These boxes highlight related points of interest to the topic being discussed. These boxes also emphasize cross-platform issues that can arise.
Structure and historical ordering
With the exception of the introductory chapter, the rest of the book is generally structured to show the chronological development (with slight variations) of technologies and abstractions related to concurrent systems. Chapter 2 covers the abstractions of processes and files, which date back to the earliest computer systems. J. Presper Eckert and John Mauchly used the file abstraction to describe stored programs in the UNIVAC (1951); earlier references in the 1940s also used this concept. Processes were key to the earliest multiprogramming systems, such as the Atlas Supervisor (1962) and CTSS (1961).
As soon as computers were able to run multiple processes concurrently, the natural next step was to make the processes communicate with each other. Chapters 3, 4, and 5 focus on this phase of historical development. IPC and networking technologies emerged in the next two decades to support this goal. Douglas McIlroy, who had previously contributed to the Multics OS, introduced the concept of pipes in UNIX (1973). Joel M. Winett defined the socket in RFC 147 (1971) as unique identifiers for transmitting data to the ARPA network. Vint Cerf introduced the term Internet in RFC 675 as part of the first specification of TCP. The TCP/IP protocol suite was later standardized in 1982, with the Internet emerging as the successor of ARPANET.
Chapters 6, 7, and 8 can be characterized as an example of the quotation, “Plus ça change, plus c’est la même chose.” Or put another way, everything old is new again. IBM OS/360 introduced threads in 1967. Edsger Dijkstra’s THE OS, which introduced semaphores as a software construct, was released the following year. Dijkstra introduced the Dining Philosophers problem in 1965. Although these techniques date back to these early years of computing, their resurgence in the 1990s and 2000s is instrumental in modern computing.
In 1985, Tony Hoare revisited the Dining Philosophers problem as part of his work on defining the Communicating Sequential Processes (CSP) language. The POSIX thread and synchronization standards were defined in POSIX.1c-1995. There were many factors driving the interest in multithreading, including the development of Linux and its use for cluster systems, as well as the impact of the “power wall” on Moore’s law and integrated circuit design.
Chapter 9 closes with an introduction to parallel and distributed computing. As with multithreading, the general concepts of distributed computing are decades old. The Internet, for instance, can be characterized as a distributed computing system. Leslie Lamport introduced distributed timestamps in 1978. However, the past two decades have brought these techniques to new heights with massively parallel supercomputers (such as Cray Titan or IBM BlueGene) and grid computing (Berkeley Open Infrastructure for Network Computing (BOINC), Folding@home, Great Internet Mersenne Prime Search (GIMPS)). Furthermore, these topics are frequently studied in stand-alone or graduate courses. As such, this chapter aims to provide a teaser or introduction to advanced study in these topics.
Chapters 2 – 9 all begin with a variant on the following diagram, which roughly summarizes the historical timeline described above. As described previously, the time frames illustrated here correspond to when the critical nature of these technologies came to the forefront of computing and computer science research, not necessarily when they were first created. Synchronization dates back to the 1960s and the foundations of much of the distributed systems field can be traced back to the 1970s and 1980s.
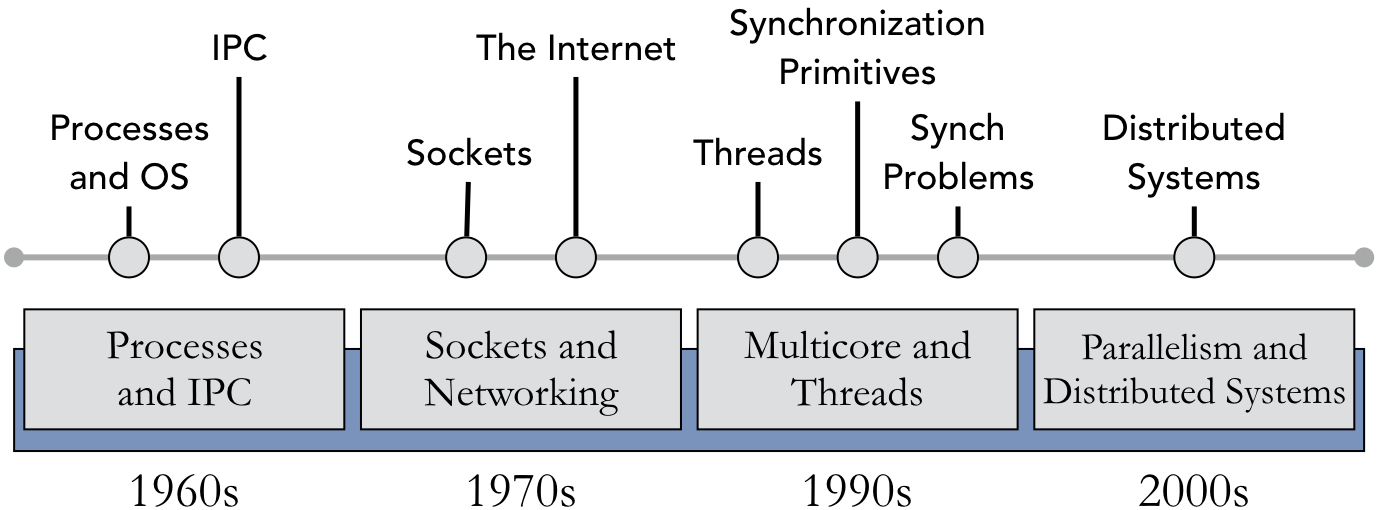
This chronological structure is not the only possible ordering for these topics. For instance, one could choose to cover threads immediately after processes. An advantage of this approach is the ability to highlight their differences as units of execution. One difficulty with this approach is the tight coupling of multithreading with the need for synchronization, due to the shared address space. A second challenge is that adding more material between the discussion of processes and IPC might make the latter seem less relevant to modern system design; why bother with processes and message queues when synchronized threads (particularly using Linux tasks) facilitate a more lightweight form of data exchange?
Another approach would be to move the networking concepts later, after threads and synchronization. This structure provides an elegant split between single-system (processes, IPC, threads) concurrency and multi-system (sockets, networks, distributed systems) concurrency. However, this approach then lessens the emphasis of sockets as a form of IPC, as sockets, (particularly kernel sockets) can be used within a single system. It also decouples the discussion of multithreading from parallelism.
In sum, there are multiple paths that these topics could be addressed in a book or a course. Readers or instructors can select which path they feel is most appropriate, bearing these tradeoffs in mind.
Funding support
This online text was supported through the VIVA Course Redesign Grant Program.