CS 470 Student Research Projects
When I teach CS 470 (Parallel and Distributed Systems), I teach it with a focus on high-performance computing (HPC) because of my background in that area. In addition, I try to cover many topics relevant to the current research areas in HPC. Thus, this course is an ideal setting for students to conduct research of their own. They do this in the form of a semester-long project conducted with my guidance.
Early in the course (but after we have covered enough introductory topics for the students to have an idea of what I expect), I ask students to submit a project idea and a list of teammates who are interested in that project. Over the first part of the semester, I work with each group to refine that idea into a concrete project proposal. The project usually includes software development, rigorous experimentation, and analysis of results. Over the second part of the semester, I continue to advise them as they complete the work. They submit a brief mid-project report and a project poster for the department symposium, and at the end they submit a final technical report (6-12 pages) alongside their code submission. For their final report I encourage them to use LaTeX and write in an academic style.
This semester-long project not only gives students a chance to experience research, but it requires them to learn how to design a scientific project, run experiments, and write a technical report about their findings. In some cases, I have recommended that exceptional projects revise and submit their final reports as papers to a regional peer-reviewed conference, where several have been accepted.
Here are some examples of projects that students have worked on in past semesters:
- Analysis of Parallel Implementations of Centrality Algorithms
Students: Kevin H. Amrein, Sam P. Carswell, and Patricia D. Soriano
This project explored parallel implementations of three network analysis algorithms for detecting node centrality: betweenness centrality, eigenvalue centrality, and degree and line importance. They wrote all solutions in the C programming language using OpenMP library for parallelization. They evaluated these implementations using five example networks. They then explored the notions of centrality encoded by each measure and compared the parallel scaling performance of each implementation. - JMU Cluster Performance Analysis
Students: S. Paige Campbell, Matthew B. Rohlf, and Michael A. Traynor
This project explored performance variation on our cluster, inspired by similar work at Kyushu University and Lawrence Livermore National Lab. Using the EP and UA benchmarks from the NAS benchmark suite, they ran single-core experiments to look for per-core variability. They also wrote their own bandwidth saturation test in MPI and used it to perform experiments that detected inter-node communication variation. They found a small amount of per-core variation but a significant amount of inter-node communication variation. - Parallelizing Shamir’s Secret Sharing Algorithm
Students: Joseph K. Arbogast and Isaac B. Sumner
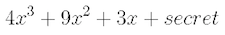 This project explored how
Shamir’s
secret sharing algorithm can be parallelized, decreasing the time
required to generate key shares for secrets shared among a large group of
participants. Using an open-source C implementation of Shamir’s algorithm
and the OpenMP multiprocessing programming interface, they parallelized
regions of the algorithm and reduced execution time significantly, seeing
near-linear speedup in both phases of the algorithm.
This project explored how
Shamir’s
secret sharing algorithm can be parallelized, decreasing the time
required to generate key shares for secrets shared among a large group of
participants. Using an open-source C implementation of Shamir’s algorithm
and the OpenMP multiprocessing programming interface, they parallelized
regions of the algorithm and reduced execution time significantly, seeing
near-linear speedup in both phases of the algorithm. - Traveling Salesman: a Heuristic Scaling Analysis
Students: Garrett L. Folks, Quincy E. Mast, and Zamua O. Nasrawt
This project analyzed two heuristics that approximate solutions to the Traveling Salesman Problem: K-Opt search and Ant Colony Optimization (ACO), with the goal of exploring how these heuristics perform when run in parallel on multiple CPU cores as well as using GPU computing. They found that an existing K-Opt implementation showed impressive parallel performance scaling, especially when executed on a GPU. They also parallelized portions of an ACO implementation and demonstrated good scaling on a CPU, conjecturing that a GPU-based implementation would be even more efficient. - Cloud Services vs. Local Clusters
Students: Brendan Armani, William Krzyzkowski, and Andrew Lee
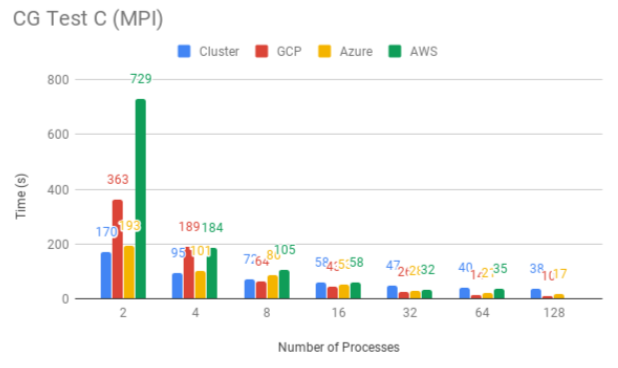 This project compared cloud service providers and explored the feasibility
and cost of running a course like CS 470 in the cloud. They compared at
three web service providers (Amazon, Google, and Microsoft) against our own
dedicated hardware cluster. They encountered and overcame many issues both
technical and bureaucratic, and found that the cloud providers generally
performed slower with similar hardware, likely due to the lack of spatial
locality. However, they found that in general the cloud would be a more
economical choice with a lower cost per semester. This result reinforces
the common wisdom that cloud services often provide a tradeoff of
performance for affordability, at least for HPC applications.
This project compared cloud service providers and explored the feasibility
and cost of running a course like CS 470 in the cloud. They compared at
three web service providers (Amazon, Google, and Microsoft) against our own
dedicated hardware cluster. They encountered and overcame many issues both
technical and bureaucratic, and found that the cloud providers generally
performed slower with similar hardware, likely due to the lack of spatial
locality. However, they found that in general the cloud would be a more
economical choice with a lower cost per semester. This result reinforces
the common wisdom that cloud services often provide a tradeoff of
performance for affordability, at least for HPC applications.
- Energy Usage of Parallel Computing
Students: Charles Hines and Kaleb Fasil
This project performed some experiments to investigate energy using in the context of parallel computing. They used Intel's RAPL system to do analysis and found (as expected) that higher degrees of parallelism lead to higher power use instantaneously but less energy use overall. - Image Analysis for Bubble Detection
Students: Nick Albright, Wesley Llamas, Brock McNerney, and Brendan Pho
 This project parallelized an image analysis tool for a physics faculty
member. The tool detects bubbles and reports the centroids and radii of all
bubbles. This group used Pthreads and OpenMP, but also experimented with
making a CUDA implementation to take advantage of a GPU. After making a
slight algorithmic improvement, they were able to speed up a process that
previously would have taken days, finishing instead in under half a minute.
This project parallelized an image analysis tool for a physics faculty
member. The tool detects bubbles and reports the centroids and radii of all
bubbles. This group used Pthreads and OpenMP, but also experimented with
making a CUDA implementation to take advantage of a GPU. After making a
slight algorithmic improvement, they were able to speed up a process that
previously would have taken days, finishing instead in under half a minute.