CS 444 Artificial Intelligence
PA3: Reinforcement Learning
Learning Objectives
After completing this activity, students should be able to:- Utilize bellman equations and q-learning to build a reinforcement learning apporach
Partners
This assignment may be completed individually or in pairs. If you are doing this in pairs, you must notify me at the beginning of the project. My expectation for pairs is that both members are actively involved, and take full responsibility for all aspects of the project. In other words, I expect that you are either sitting or virtually together to work, and not that you are splitting up tasks to be completed separately. If both members of the group are not able to fully explain the code to me, then this does not meet this expectation.Provided Files
Download this zip archive pa3.zip which contains all the code and supporting files. Here is a short summary of what is contained within the zip file:| Files you will edit: | |
| valueIterationAgents.py | A value iteration agent for solving known MDPs |
| (NOT FOR THIS LAB)qlearningAgents.py | Q-learning agents for Gridfworld and Crawler. |
| (NOT FOR THIS LAB) analysis.py | A place to put your answers. |
| Files you might want to look at: | |
| mdp.py | Defines methods on general MDPs. |
| learningAgents.py | Defines the base classes for ValueEstimationAgent and QLearningAgent, whch your agents will extend |
| util.py | Utilities, including util.Counter, which is particularly useful for Q-learners |
| gridworld.py | The gridworld implementation |
| featureExtractors.py | Classes for extracting features on (state, action) pairs. Used for the approximate Q-learning agent (in qlearningAgents.py |
| Support files you can ignore: | |
| environment.py | Abstract class for general reinforcement learning environments. Used by gridworld |
| graphicsGridworldDisplay.py | Gridworld graphical display |
| graphicsUtil.py.py | Graphic utility |
| textGridworldDisplay | plug-in for the gridworld text interface |
| crawler.py | The crawler code and test harness. You will run this but do NOT edit. |
| graphicsCrawlerDisplay.py | GUI for the crawler robot |
| autograder.py | Project autograder |
| testParser.py | Parses autograder test and solution files |
Value Iteration
Recall that the value iteration state update equation is:

- computeActionFromValues(state) computes the best action according to the value function given by self.values.
- computeQValueFromValues(state, action) returns the Q-value of the (state, action) pair given by the value function given by self.values.
Submission and Policies
You must submit the following files:ValueIterationAgents.pyto Canvas .
Evaluation: Your code will be autograded for technical correctness. Please do not change the names of any provided functions or classes within the code, or you will wreak havoc on the autograder. However, the correctness of your implementation – not the autograder’s judgements – will be the final judge of your score. If necessary, I will review and grade assignments individually to ensure that you receive due credit for your work.
Academic Dishonesty: Your code will be checked against other submissions in the class for logical redundancy. If you copy someone else’s code and submit it with minor changes, it will be detected. These cheat detectors are quite hard to fool, so please don’t try. I trust you all to submit your own team's work; please don’t let us down.
Getting Help: You are not alone! If you find yourself stuck on something, contact me. Office hours and Piazza discussion forum are there for your support; please use them. If you can’t make office hours, let me know and I will schedule a meeting with you. I want these projects to be rewarding and instructional, not frustrating and demoralizing. But, I don’t know when or how to help unless you ask.
Project Overview
MDPs
You will implement the value iteration algorithm and
test it in the gridworld setting discussed in class. For part 1,
you will need to modify valueIterationAgents.py and
implement the following methods:
- runValueIteration. This method is called from the constructor. You should use the computeQValuesFromValues in this method.
- computeQValueFromValues
- computeActionFromValues
-i command option) and stored within self.iteration
in the ValueIterationAgent class. The following descriptions
are provided for Vk.
Important: Use the “batch” version of value iteration where each vector Vk is computed from
a fixed vector V(k-1) (like in lecture), not the “online” version where one single weight
vector is updated in place. This means that when a state’s value is updated in iteration
k based on the values of its successor states, the successor state values used in the value
update computation should be those from iteration k − 1
(even if some of the successor states had already been updated in iteration k
).
Note: A policy synthesized from values of depth k (which reflect the next k rewards) will actually reflect
the next k + 1 rewards (i.e. you return π(k+1).
Similarly, the Q-values will also reflect one more reward than the values (i.e. you return
Q(k+1).
You should return the synthesized policy π(k+1).
Hint: You may optionally use the util.Counter class in util.py, which is a dictionary with a default value of zero. However, be careful with argMax: the actual argmax you want may be a key not in the counter!
Note: Make sure to handle the case when a state has no available actions
in an MDP (think about what this means for future rewards).
To test your implementation, run the autograder:
python gridworld.py -a value -i 100 -k 10python autograder.py -q q1python gridworld.py -a value -i 5
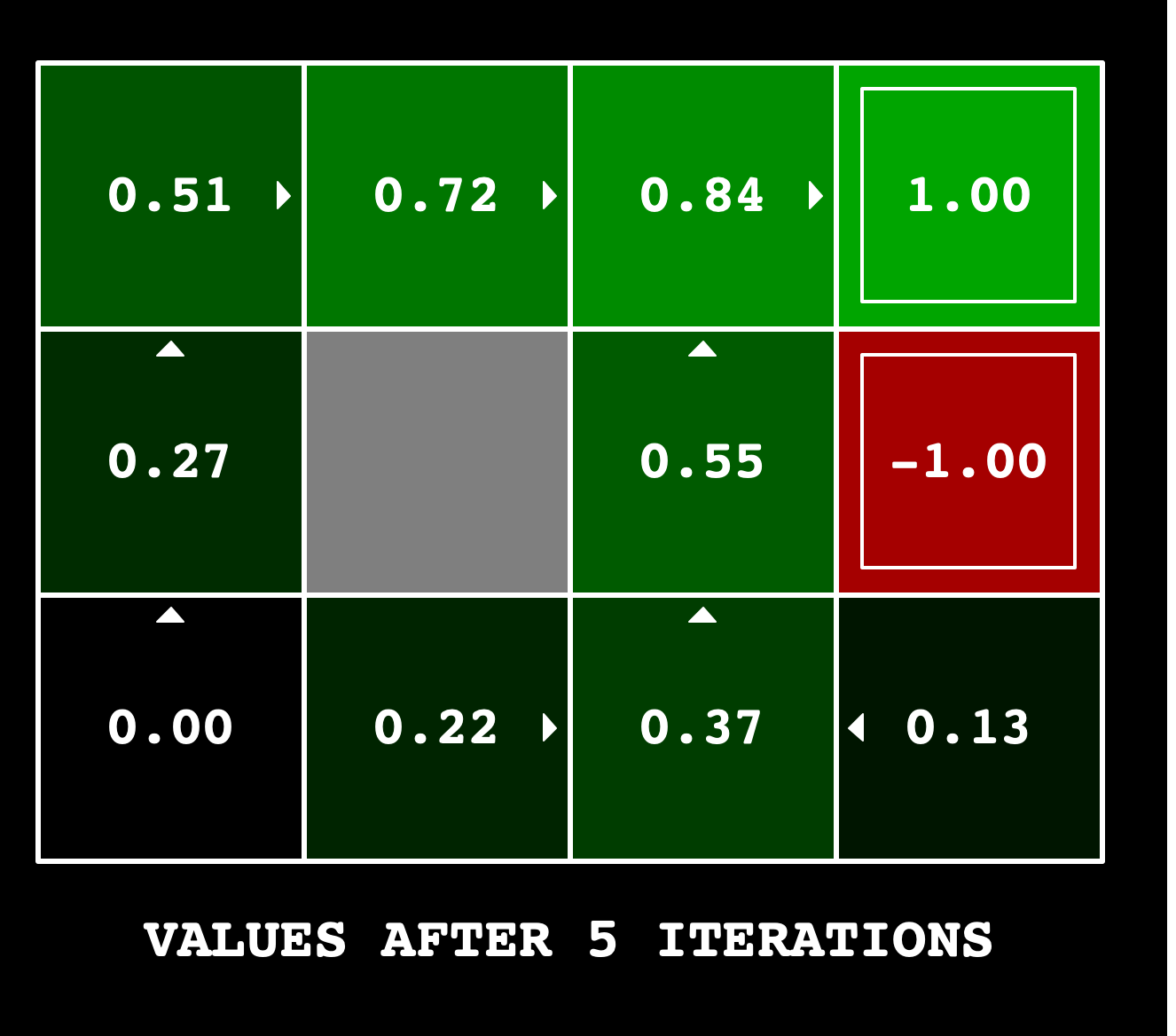
Submissions will be graded according to the following rubric:
| Passes Unit Tests | 90% |
| Coding style | 10% |