Preventing Overfitting - Weight Penalities
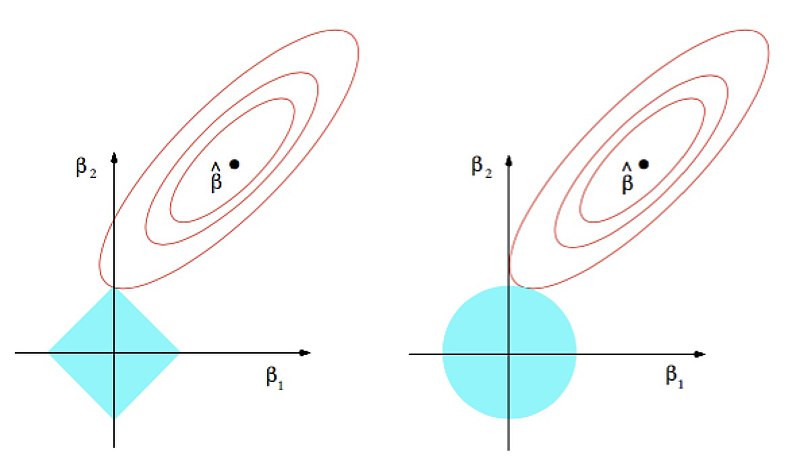
L2 Regularization:
\(L_\lambda(\mathbf{w}) = L(\mathbf{w}) + \lambda \|\mathbf{w}\|_2^2\)
Also knowns as weight decay or Ridge regression
L1 Regularization:
\(L_\lambda(\mathbf{w}) = L(\mathbf{w}) + \lambda |\mathbf{w}|\)
 https://commons.wikimedia.org/wiki/File:Regularization.jpg
https://commons.wikimedia.org/wiki/File:Regularization.jpg

