Review: Linear Regression
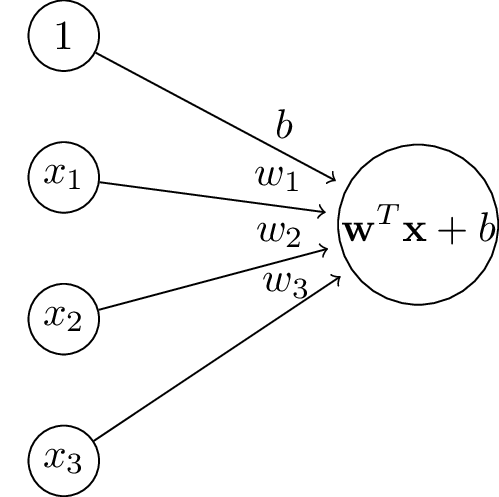
The goal was to find weight values to minimize MSE on some training data: fitting a hyperplane.
The goal was to find weight values to minimize MSE on some training data: fitting a hyperplane.
This is the logistic or sigmoid function: \[\sigma(z) = \frac{e^z}{1 + e^{z}} = \frac{1}{1 + e^{-z}}\]
It looks like this:

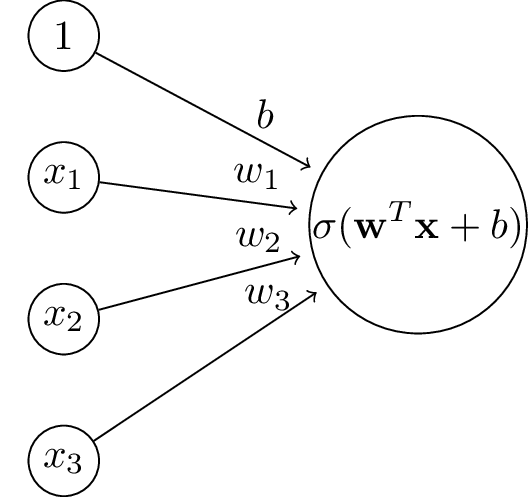
After applying a sigmoid non-linearity we can interpret the output as a probability.
The logistic function has a simple derivative:
\[\sigma'(x) = \sigma(x)(1 - \sigma(x))\]

Zero and one are numbers, so there is no reason we couldn’t use the loss function we used for linear regression: \[E(\mathbf{w}) = \sum_{i=1}^n (y_i - \sigma(\mathbf{w}^T\mathbf{x} + b))^2\]
Here is how the two loss functions compare:
