Value Iteration Lab
Categories:
3 minute read
Value Iteration Gridworld
Introduction
In this lab, you will construct the code to implement value iteration in order to compute the value of states in a MDP.
Files
-
valueIteration.zip
in a directory. In this lab, you will be changing the
valueIterationAgents.pyfile.
Coding
Construct code for a MDP that is computing using value iteration. You will need to code the following methods in valueIterationAgents.py:
runValueIteration. This method is invoked from the constructor.- computeQValueFromValues
- *computeActionsFromValues
Recall that the value iteration state update equation is: $$ V_{k+1} = \max_{a}\sum_{s’}T(s,a,s’)[R(s,a,s’) + \gamma V_{k}(s’)] $$
When implementing value iteration, you are only being asked to
run for the number of iterations requested on the command line (so, do not run until convergence).
The number of iterations to run value iteration is an argument (specified via the -i command option) and stored within self.iteration in the ValueIterationAgent class.
You should also look at the __init__ method, as it shows some VERY useful methods within
the self.mdp object that you will need. This is an offline planner.
Important:
- Use the “batch” version of value iteration where each vector $V_k$ is computed from a fixed vector $V(k-1)$ which is how this was described during lecture (not the “online” version we will discuss that is required for reinforcement learning). This means that when a state’s value is updated in iteration k based on the values of its successor states, the successor state values used in the value update computation should be those from iteration k − 1 (even if some of the successor states had already been updated in iteration k).
- A policy synthesized from values of depth $k$ (which reflect the next $k$ rewards) will actually reflect the next $k + 1$ rewards (i.e. you return $\pi(k+1)$. Similarly, the Q-values will also reflect one more reward than the values (i.e. you return $Q(k+1)$. You should return the synthesized policy $\pi(k+1)$.
- Hint: You may optionally use the
util.Counterclass inutil.py, which is a dictionary with a default value of zero. However, be careful with argMax: the actual argmax you want may be a key not in the counter! - Note: Make sure to handle the case when a state has no available actions in an MDP (think about what this means for future rewards).
- The docstring comments above the functions also mention this, but when no states are available do to a state being a terminal state, you can return that no actions are possible and the value is zero.
To test your implementation, run the autograder:
python gridworld.py -a value -i 100 -k 10
The following command loads your ValueIterationAgent, which will compute a policy and execute it 10 times. Press a key to cycle through values, Q-values, and the simulation. You should find that the value of the start state (V(start), which you can read off of the GUI) and the empirical resulting average reward (printed after the 10 rounds of execution finish) are quite close.
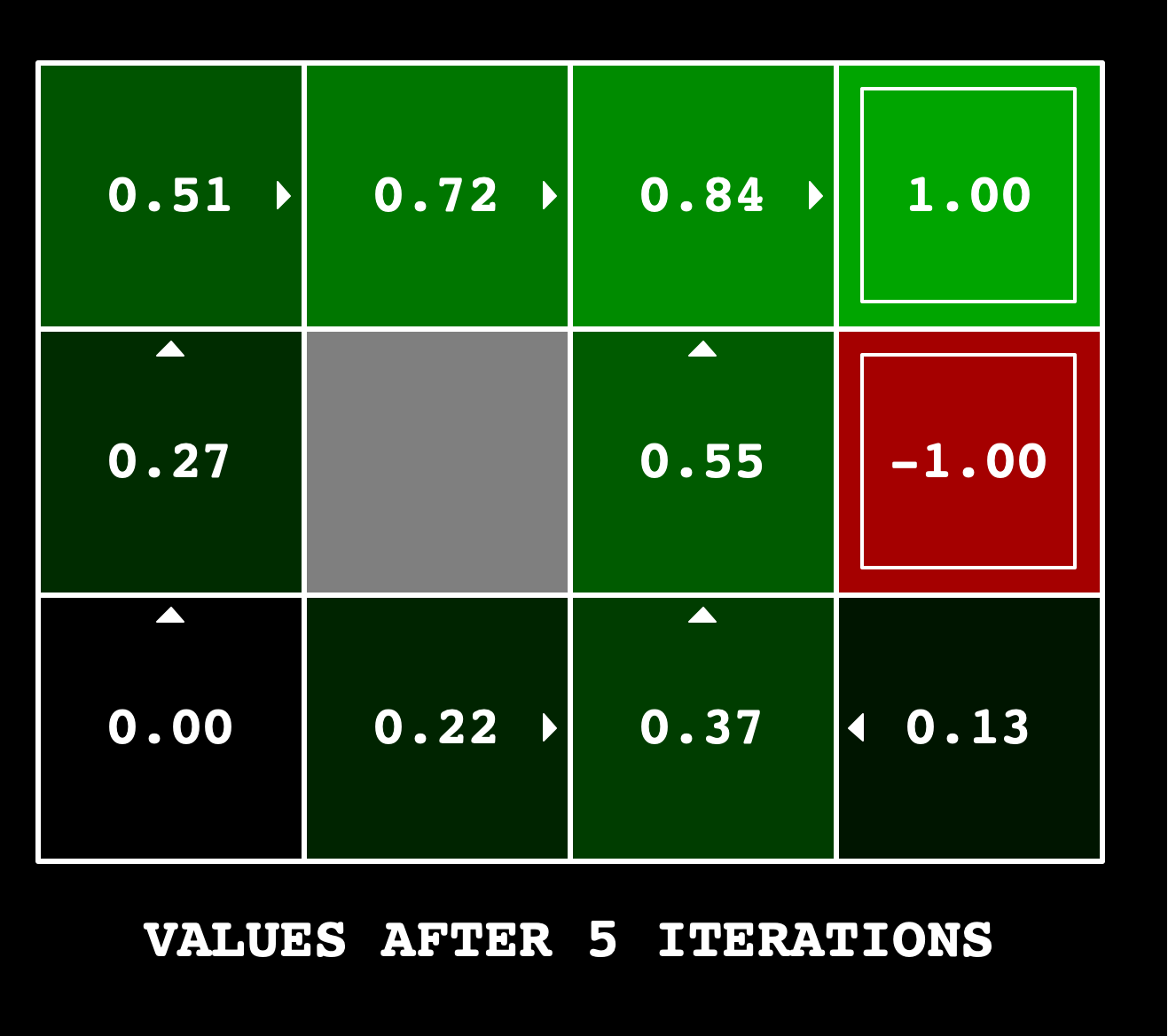
Running the following command should give the values that are shown at the top of this assignment.
python gridworld.py -a value -i 5
Grading:
| Project Part | Points |
|---|---|
| Autograder score | 23 |
| Code Review/Doc/Comments | 2 |
To run the autograder, you can use this command:
python autograder.py -q q1
Submitting
Submit your completed version of multiAgent.py
through Gradescope to the Value Iteration assignment.
However, you can test your code locally using the procedures listed above.