
PA3 - Decaf Parser
Goal
The goal of our semester-long project is to gain experience in compiler implementation by constructing a simple compiler. We will be implementing a compiler for a variant of the well-known Decaf language, which is a simple Java-like procedural programming language.
The goal of this part of the project is to gain experience specifying syntactic structures by using a parser generator to build a complete front-end for our Decaf compiler.
Part 1 - ANTLR Specification
For this part of the assignment, you will add parser rules to your ANTLR lexer specification from the first project.
We will be using a variant of the grammar from the Decaf language specification. However, we will be making a few minor modifications. Here are the most significant changes:
- As described in the document, "Program" is not a keyword; rather it is an identifier with special meaning: it must be the name of the top-level class. However, this rule should be enforced by the analyzer, not the parser.
- We will be including "while" loops as well as "for" loops. This makes the language more expressive and enables easier general iteration.
- We will only be including a single assignment operator ("="). The other two ("+=" and "-=") are merely syntactic sugar, complicating the AST representation without adding much of interest to the implementation.
Here is the final version of the grammar that we will use for this project:
| <program> | → | class ID '{' <field_decl>* <method_decl>* '}' |
| <field_decl> | → | <vtype> { ID | ID '[' <int_literal> ']' }+, ';' |
| <method_decl> | → | { <vtype> | void } ID '(' [ { <vtype> ID }+, ] ')' <block> |
| <block> | → | '{' <var_decl>* <statement>* '}' |
| <var_decl> | → | <vtype> ID+, ';' |
| <vtype> | → | int | boolean |
| <statement> | → | <location> '=' <expr> ';' |
| | | <method_call> ';' | |
| | | if '(' <expr> ')' <block> [ else <block> ] | |
| | | for ID '=' <expr> ',' <expr> <block> | |
| | | while '(' <expr> ')' <block> | |
| | | return [ <expr> ] ';' | |
| | | break ';' | |
| | | continue ';' | |
| | | <block> | |
| <method_call> | → | ID '(' [ <expr>+, ] ')' |
| | | callout '(' STRING [ ',' <callout_arg>+, ] ')' | |
| <location> | → | ID |
| | | ID '[' <expr> ']' | |
| <expr> | → | <location> |
| | | <method_call> | |
| | | <literal> | |
| | | <expr> <bin_op> <expr> | |
| | | '-' <expr> | |
| | | '!' <expr> | |
| | | '(' <expr> ')' | |
| <callout_arg> | → | <expr> | STRING |
| <bin_op> | → | '+' | '-' | '*' | '/' | '%' | '<' | '>' | '<=' | >=' | '==' | '!=' | '&&' | '||' |
| <literal> | → | <int_literal> | CHAR | BOOLEAN |
| <int_literal> | → | DEC | HEX |
The grammar above uses the following metanotation, which is the same notation as the reference grammar in the document, except that lexer-level terminal categories are listed in all-caps. You should have the terminal categories defined already from the first project.
| Notation | Description |
|---|---|
| <foo> | non-terminal |
| foo | terminal keyword (described by literal string) |
| 'x' | terminal operator (described by literal string) |
| FOO | terminal class (described by regular expression) |
| [ x ] | optional; i.e., zero or one occurrences |
| x* | kleene closure; i.e., zero or more occurrences |
| x+, | comma-separated list of one or more occurrences |
| { } | grouping operators |
| | | alternation |
Most of the grammar can be copied nearly verbatim from the description above. However, there are a few places where you will need to modify it:
- You will need to find a clean way to represent the comma-separated notation from the above grammar.
- You will need to modify the <expr> definition to enforce the following precedence groups (listed high-to-low):
| Operators | Description |
|---|---|
| - | unary negation |
| ! | logical NOT |
| * / % | multiplication, division, modular division |
| + - | addition, subtraction |
| < > <= >= | relational operators |
| == != | equality operators |
| && | logical AND |
| || | logical OR |
I recommend using ANTLRWorks 2 to edit your grammar file. It provides a very nice DFA-like view of your productions as you edit them. To enable this view, choose "Syntax Diagram" from the "Window" menu. I suggest docking it in the left or bottom panel and leaving it enabled while you complete Part 1 of the project.
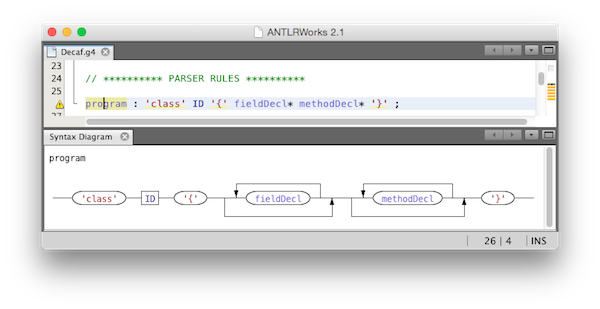
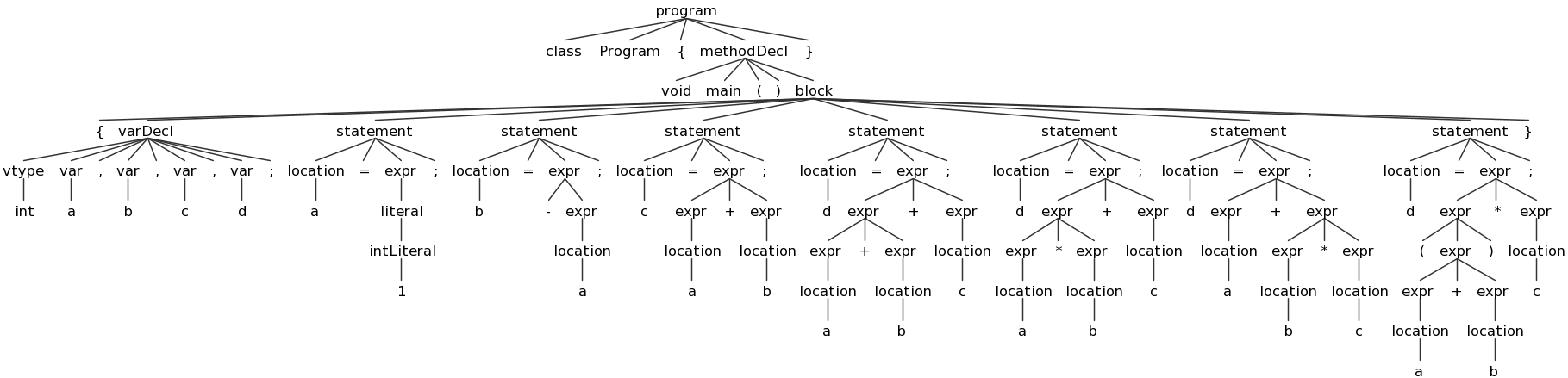
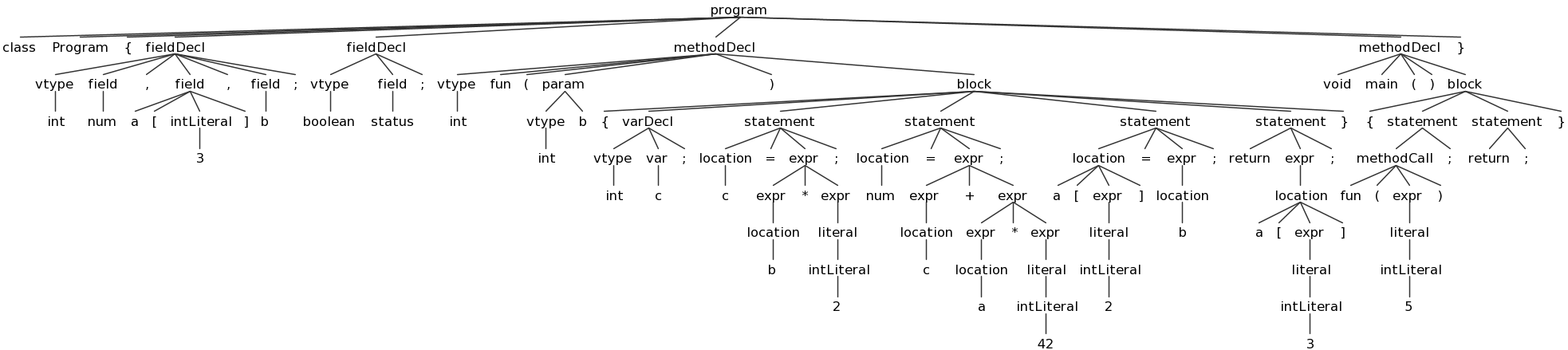
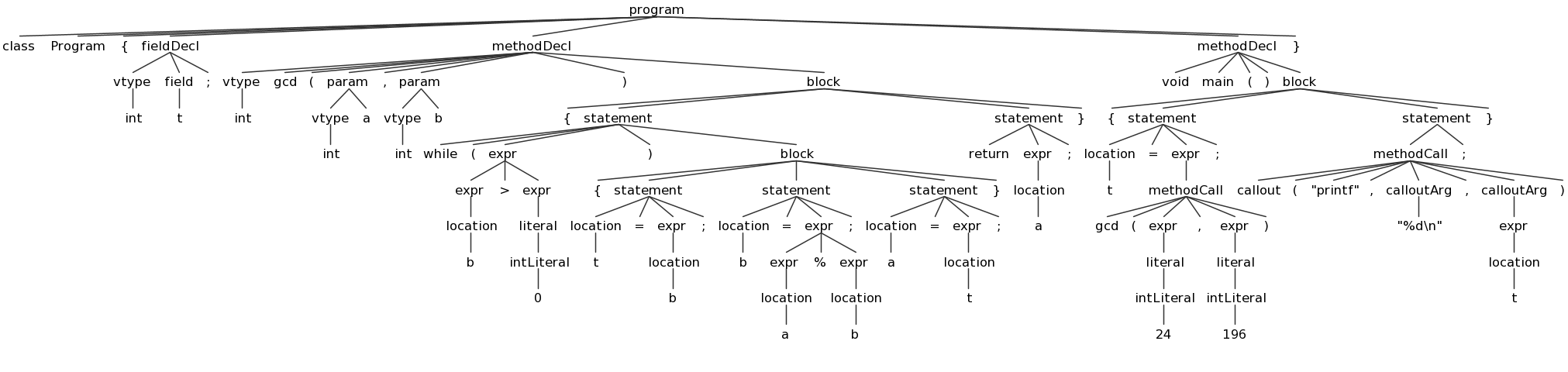
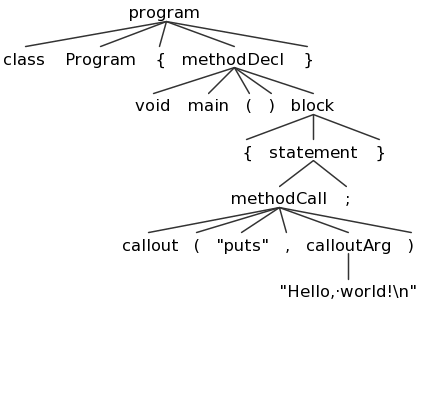
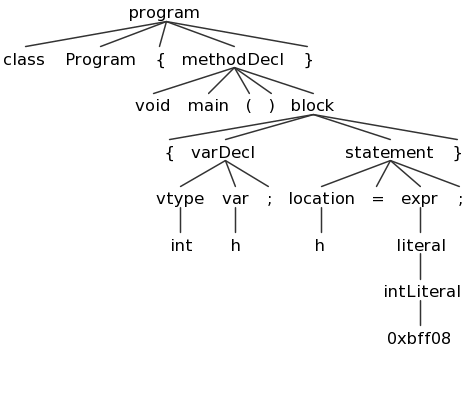
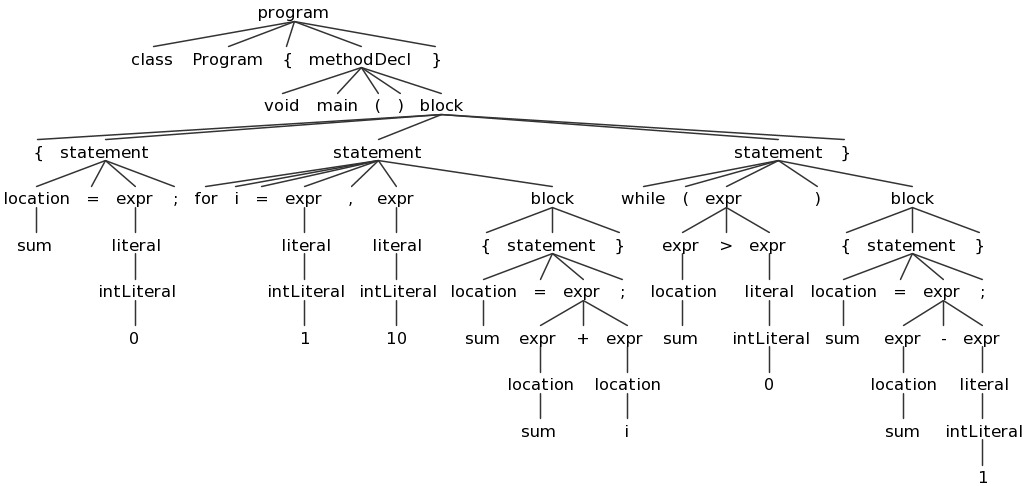
ANTLRWorks also provides a way to test your grammar on a Decaf program. To do this, choose "Run in TestRig" from the "Run" Menu. Create a sample Decaf program and select it as the input file, choose your "program" non-terminal as the start rule, and choose "Finish". If there are no errors in your grammar or Decaf program, it will display a graphical view of the resulting parse tree:
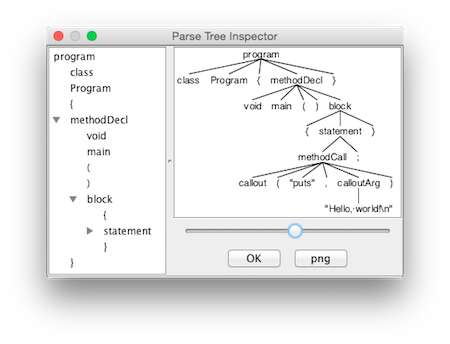
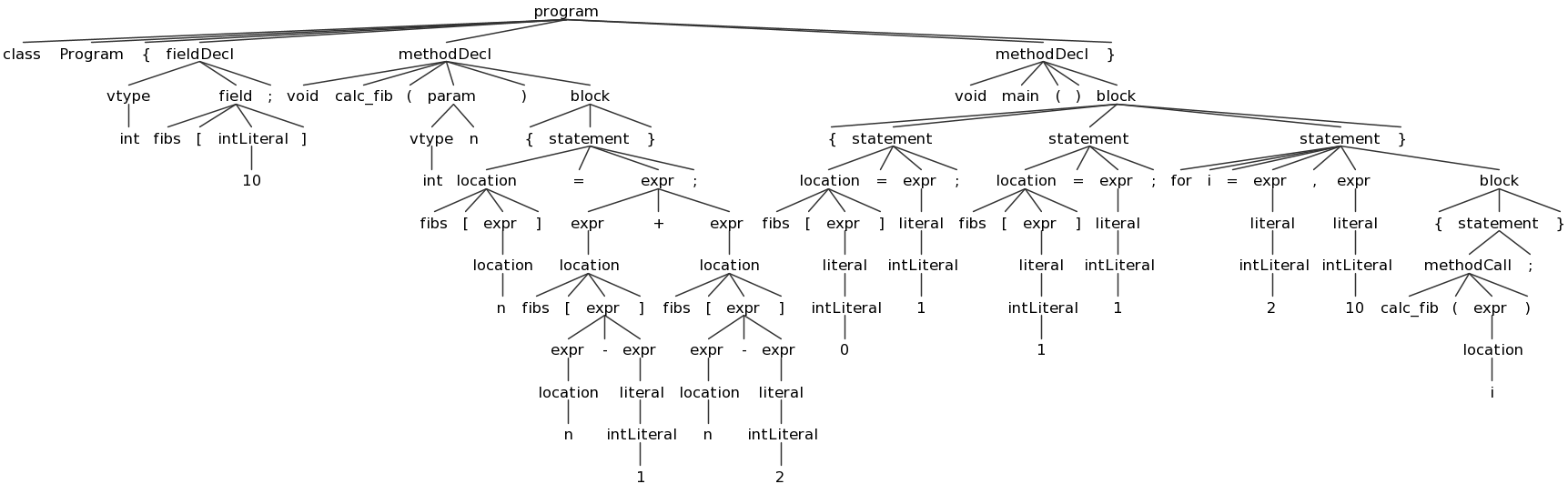
You can save these images using the "png" button; I recommend doing so for several test Decaf prorams and referring to these images and using them while you work on Part 2. Here are some sample Decaf programs:
array.decaf(tree) (AST)empty.decaf(tree) (AST)expr.decaf(tree) (AST)fields.decaf(tree) (AST)gcd.decaf(tree) (AST)hello.decaf(tree) (AST)hex.decaf(tree) (AST)loops.decaf(tree) (AST)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
You may also download all sample programs in a single zip file: decaf_samples.zip.
Part 2 - AST Conversion
Once your grammar specification is complete, write a parse tree visitor that converts the parse tree to an equivalent abstract syntax tree (AST).
To ensure a standard AST representation across all submissions and to provide a common base for subsequent projects (the analyzer and code generator), I am providing an AST node framework specification in the form of a Python file with definitions for AST nodes:
Please read the AST specification file carefully and ensure that you understand the structure that you need to build. IMPORTANT: Do NOT modify DecafAST.py!
Then, write a routine that converts the parse tree from ANTLR into an AST
structure. ANTLR produces a visitor interface (in DecafListener.py)
that you can subclass in order to build your AST converter. I recommend using
the following Python stub:
from DecafAST import *
from DecafLexer import DecafLexer
from DecafParser import DecafParser
from DecafListener import DecafListener
class DecafASTConverter(DecafListener):
def __init__(self):
self.mainAST = None
def enterProgram(self, ctx):
self.mainAST = ASTProgram()
def getAST(self):
return self.mainAST
The listener interface contains "enter" and "exit" methods that are called
whenever an instance of the corresponding parse node is visited during a tree
traversal. You should use these methods to construct an AST that corresponds to
the elements from the parse tree. You will need to determine the cleanest way to
perform this conversion, and decide what intermediate pieces of data to store in
the DecafASTConverter class while traversing the tree.
You will need to understand the "context" objects that ANTLR produces in
order to obtain all of the information that you need from the parse tree. These
context objects essentially represent parse tree nodes, and are defined in the
DecafParser.py file that is produced when you run ANTLR.
The "ctx" parameter in the visitor methods is a reference to the
corresponding parse tree node. This object contains accessors for children
elements of the parse tree. You may access them directly with
getChildren or getChild, or you may use the more
specific typed methods for each production (i.e., ID() or
methodDecl() to access the children of a "program" context). To
access the actual character data associated with a terminal, you will need to
call the getText() method on that terminal.
To simplify the creation of the AST, I recommend "annotating" the parse tree structure (of *Context objects) with snippets of ASTs as you build them. In this sense, the AST snippets represent synthesized attributes of the parse tree.
You must also modify your compiler driver from the first project so that it
performs both phases of the compiler front-end (lexing and parsing). The driver
for this phase of the project should take a filename as a command-line parameter
and print the parsed and converted AST to standard output (using the
formatTree() method). Here is some example Python driver code:
import sys
from antlr4 import *
from DecafAST import *
from DecafLexer import DecafLexer
from DecafParser import DecafParser
from DecafASTConverter import DecafASTConverter
def main(argv):
# run lexer
input = FileStream(argv[1])
lexer = DecafLexer(input)
# run parser
stream = CommonTokenStream(lexer)
parser = DecafParser(stream)
parse_tree = parser.program()
# convert to AST
converter = DecafASTConverter()
walker = ParseTreeWalker()
walker.walk(converter, parse_tree)
ast = converter.getAST()
# print AST
print(ast.formatTree(0))
if __name__ == '__main__':
main(sys.argv)
You do not need to build symbol tables at this time; you will do that as part of the analyzer component (PA4).
You may modify the grammar specification from Part 1 if you wish in order to make Part 2 easier, as long as your modifications do not change the overall language accepted by the parser.
Sample Input
// gcd.decaf
class Program {
int t;
// uses euclid's algorithm
int gcd(int a, int b) {
while (b > 0) {
t = b;
b = a % b;
a = t;
}
return a;
}
// program entry point
void main() {
t = gcd(24, 196);
callout("printf", "%d\n", t);
}
}
Sample Output
- Program
- FieldDecl name=t type=int size=0
- MethodDecl name=gcd type=int params={a:int, b:int}
- Block
- WhileLoop cond=(b>0)
- Block
- Assignment loc=t expr=b
- Assignment loc=b expr=(a%b)
- Assignment loc=a expr=t
- Return
- Expr [loc]
- Location name=a
- MethodDecl name=main type=void params={}
- Block
- Assignment loc=t expr=gcd(24, 196)
- MethodCall name="printf" [callout]
- Literal type=string value="%d\n"
- Expr [loc]
- Location name=t
Submission
PART 1 DUE: Friday, Feb 27, 2015, at 23:59 (11:59PM) EST
PART 2 DUE: Friday, Mar 6, 2015, at 23:59 (11:59PM) EST
Recommended file names (for Python):
Decaf.g4 (grammar, project part 1)
DecafLexer.py (auto-generated using ANTLR4)
DecafParser.py "
DecafListener.py "
DecafCompiler.py (driver, provided above)
DecafAST.py (AST framework, provided above)
DecafASTConverter.py (converter, project part 2)
For part 1, submit only your Decaf.g4 file on canvas.
For part 2, submit a zip or tarball with your complete solution on Canvas. Your code must compile and work on the class server. Part of your grade will be based on automated testing and part will be based on style considerations. Please make sure that your project adheres to the specification exactly to avoid difficulties with the automated testing framework, and make sure that your code is clean and documented.