Project 4 - Distributed Hash Table
Introduction
The primary purpose of this assignment is to gain experience with mixed-technology parallel/distributed computing using both Pthreads and MPI. The secondary purpose is to gain experience with the concepts of a remote procedure call (RPC) and a distributed hash table (DHT).
Description
The starter files may be copied from /shared/pa4-dht.tar.gz on
the cluster, and consist of the following files:
-
local.h / local.c- Header and implementation for a very simple local hash table. Note that there is no "get" functionality, only "put." The correctness of the code is verified by dumping the hash table at the end of execution. You should NOT edit this file. -
main.c- Driver program. This includes client code that reads through an input file (given as a command-line argument) and executes the commands in that file as specified below. You should NOT edit this file. -
dht.h- Header for a distributed hash table. You should NOT edit this file. -
dht.c- Implementation for a distributed hash table. Currently, these functions merely delegate to their local versions (in other word, they're currently just wrappers). This means that only the rank 0 process will do anything and it will process all commands locally. Your task is to turn this implementation into a distributed implementation using Pthreads and MPI.
Here is an example input file:
proc 0 foo 5 bar 99 cat 7 proc 1 baz 1 aaa 2
This input file contains instructions for two processes (rank 0 and rank 1). Rank 0 will request the storage of three key-value pairs ("foo:5", "bar:99", "cat:7") and rank 1 will request the storage of two key-value pairs ("baz:1", "aaa:2").
In the provided serial version, there is no Pthread or MPI code and it runs only the commands listed for rank 0. All key-value pairs are stored locally.
In the distributed version, every key should be assigned an "owner" via a hash function that takes the ASCII value of the first letter and performs a division modulo the total number of processes. For instance, if there are four processes, key "foo" will map to rank 2 because the ASCII code for 'f' is 102 and 102 mod 4 = 2.
If a process needs to "put" a value into the hash table of another process, it should do so using a remote procedure call via MPI. You may design the RPC protocol however you like, but I suggest keeping things as simple as possible.
Your solution must work reliably for up to 32 processes across four nodes. Each MPI process should consist of two threads: a client (the main thread) and a server. You should NOT modify any of the client code, which reads the input file and executes the appropriate "put" instructions.
However, you are responsible for spawning and managing
the server thread. You should do this in dht_init() and
dht_destroy(), respectively. The server thread should execute a
loop that waits for "put" remote procedure calls from other processes and
delegates them to the local "put" method. The following diagram illustrates this
communication if the above file is run with four processes:
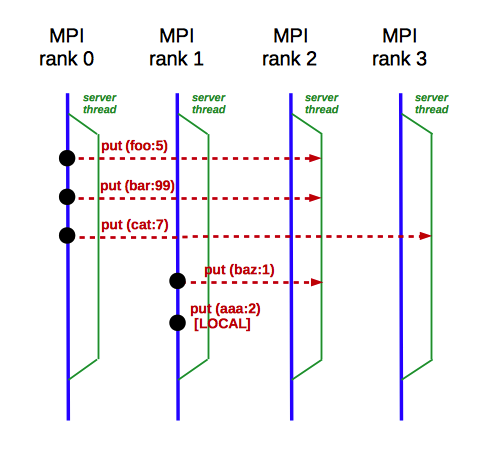
At the end of execution, every MPI process should dump its hash table to a
file named "dump-XX.txt" where XX is the rank of the process. You
can easily view all these files after execution using "cat dump-*.txt".
A correct output for the input file listed above (run with four processes) is the
following (minus the comments in the right margin, added here to clarify where
each file begins):
Process 0 # dump-0.txt Process 1 # dump-1.txt Pair #0 Key="aaa" Value=2 Process 2 # dump-2.txt Pair #0 Key="baz" Value=1 Pair #1 Key="foo" Value=5 Pair #2 Key="bar" Value=99 Process 3 # dump-3.txt Pair #0 Key="cat" Value=7
These files should not have any extraneous output (debugging output, etc.). The ordering of keys within a local hash table does not matter, so there could be multiple "correct" answers for a given input file depending on how messages get re-ordered during execution.
MPI Notes
WARNING: There appears to be some issue with
multithreaded MPI programs on our cluster. Some investigation leads me to
suspect the installed version of OpenMPI. Thus, I recommend that you use MPICH
instead of OpenMPI for this project. To use MPICH, use the following code
wherever you would normally use "module load mpi":
export SPACK_ROOT=/shared/spack export PATH=$SPACK_ROOT/bin:$PATH source $SPACK_ROOT/share/spack/setup-env.sh spack load mpich
Be sure you do not also have OpenMPI loaded. If you had it in your
.bash_profile or .bashrc script, you should delete it.
If you have an existing shell that you want to re-use, you can unload the
OpenMPI module using the following command:
module unload mpi
Don't forget to initialize and finalize MPI! Because you are using threads
in addition to MPI, you will want to initialize MPI using
MPI_Init_thread() instead of MPI_Init(). Here is an
example:
int provided;
MPI_Init_thread(NULL, NULL, MPI_THREAD_MULTIPLE, &provided);
if (provided != MPI_THREAD_MULTIPLE) {
printf("ERROR: Cannot initialize MPI in THREAD_MULTIPLE mode.\n");
exit(EXIT_FAILURE);
}
This snippet requests the full multithreaded mode
(MPI_THREAD_MULTIPLE). There are actually three levels of
multithread support in MPI, and unfortunately our installation of OpenMPI only
supports the third level (MPI_THREAD_SERIALIZED). You can verify
this yourself by checking the value of provided after the init call
(as in the above snippet). Thankfully, MPICH supports the
MPI_THREAD_MULTIPLE level, so you should use it for this project.
Hints
HINT: Don't forget to #include <mpi.h> in
dht.c!
HINT: You will need to make sure that the server threads do not
terminate until all nodes are done sending messages. The most common way to do
this cleanly is to have the server thread go into an "infinite" loop, stopping
when it receives a message (or messages) indicating that it is safe to do so.
You should NOT use any of the Pthread methods for forcefully killing the thread,
such as pthread_cancel() or pthread_kill().
HINT: Don't over-complicate! The reference solution is around 150
lines (as a reminder, the boilerplate for dht.c is already 40
lines).
HINT: If your job hangs on the cluster and you get a "Stale file handle" error, just try it again. This is likely an unresolved NFS issue.
Grading Criteria
Your submission will be graded on a combination of correctness, functionality, elegance, style, and documentation. Here is a tentative grading rubric:
| Grade | Description | Requirements |
|---|---|---|
| A | Exceptional |
|
| B | Good |
|
| C | Satisfactory |
|
| D | Deficient |
|
| F | Unacceptable |
Submission
You should submit your modified program as dht.c on Canvas by
the due date. You should not submit your Makefile or anything else, and your
program must compile and run on the cluster using the reference version of the
other files.
All submitted code should be elegant, clean, consistent, and well-documented. The code I have provided uses 4-space indentation and the 1TBS style. If you choose to reformat the file to match your own style preferences, make sure you apply the changes throughout.
Peer Reviews
One of the goals of this course is to encourage good software development practices, especially when building a parallel or distributed software system. For this project, you will be assigned two other random students in the course. You must review their code and offer constructive feedback according to the given rubric.
After the submission deadline, I will assign you two other submissions to review on Canvas. I expect you to review two distinct submissions that are not your own; I will do my best to ensure that the assignments work out but sometimes Canvas does not cooperate. It is your responsibility to inform me immediately if you have been assigned yourself, your partner, or two other same-team partners to review.
To complete the peer review, submit a Canvas comment on the submission with your assessment of the submission according to the provided code review guidelines. I expect at least two paragraphs per review with detailed observations and an assigned overall numeric score. You will be graded on the quality, thoroughness, and professional tone of your review. The peer reviews are due one week after the original project due date.